
关于比较与跳转
cmp eax,ebx会比较两个寄存器,然后根据两个比较结果来来设置处理器标志位(例如“大于”标志)- 执行到
jg .L2时,这条指令会检查处理器中“大于”的标志位- 如果“大于”标志位被设置了,则跳转到标签
.L2所在到位置继续执行后续指令 - 如果“大于”标志位没有被设置,则不会发生跳转,而是继续顺序执行下一条指令
- 如果“大于”标志位被设置了,则跳转到标签
|
1 2 3 4 5 |
cmp eax, ebx jg .L2 ; 如果 eax 大于 ebx,则跳转到标签 .L2 ; 其他指令... .L2: ; 这里是 .L2 标签的位置,可以是跳转的目标 |
new and delete
代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#include <new> class sss { char a; int b; }; int main() { sss * pss = new sss(); delete pss; pss = nullptr; return 0; } |
汇编
- 环境:
godbolt- `
x86-64 gcc 13.2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
main: push rbp mov rbp, rsp sub rsp, 16 mov edi, 8 call operator new(unsigned long) mov BYTE PTR [rax], 0 mov DWORD PTR [rax+4], 0 mov QWORD PTR [rbp-8], rax mov rax, QWORD PTR [rbp-8] test rax, rax je .L2 mov esi, 8 mov rdi, rax call operator delete(void*, unsigned long) .L2: mov QWORD PTR [rbp-8], 0 mov eax, 0 leave ret |
解析
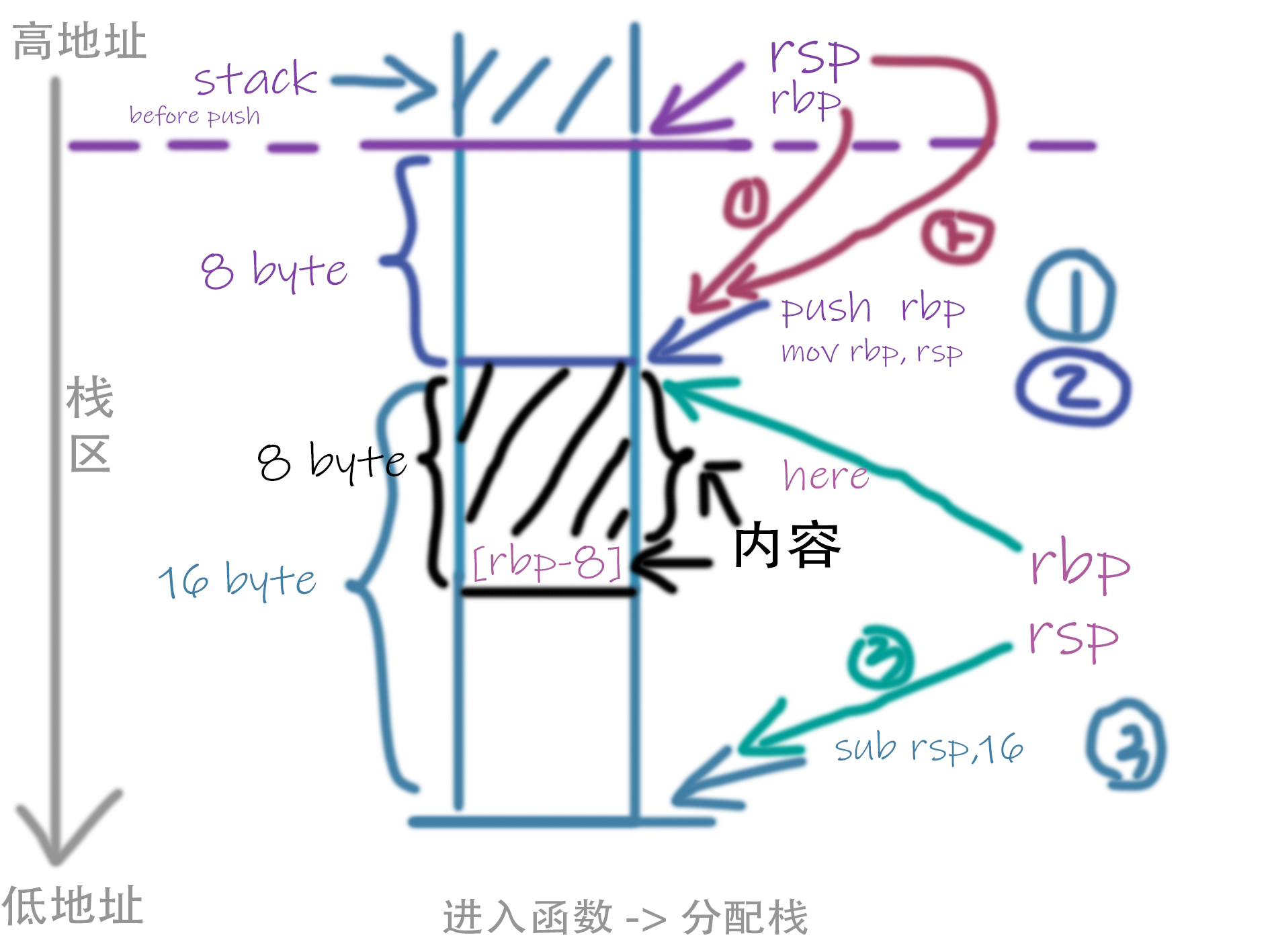
- 创建堆栈,并开辟栈空间,用于给局部变量和临时数据使用
|
1 2 3 |
push rbp mov rbp, rsp sub rsp, 16 |
new的参数1,new8个字节大小
|
1 2 |
mov edi, 8 call operator new(unsigned long) |
rax存了返回值,也就是new出来的空间的地址- 结合源码,
char占1个字节,int占4个字节,这里是把new出来的空间那个地址开始,先初始化了一个字节- 然后从开始地址往后4个地址,初始化了4个字节
- 也就是说,用于对齐的3个字节,并没有被初始化
|
1 2 |
mov BYTE PTR [rax], 0 mov DWORD PTR [rax+4], 0 |
byte ptr:表示一个字节word ptr:表示一个字,两个字节dword ptr:表示两个字,四个字节qword ptr:表示四个字,八个字节rax这里还保存的是new出来的空间的地址,把这个堆区的内存地址保存到栈区空间:- 从
[rbp-8]这里开始,往后8个字节 - 也就是我们的局部变量pss
- 从
|
1 |
mov QWORD PTR [rbp-8], rax |
- 将栈区保存的堆区地址加载到寄存器
rax中,以便后续可以访问或操作分配的内存
|
1 |
mov rax, QWORD PTR [rbp-8] |
- 因为要
delete,所有要测试局部变量pss是否为空(没有delete操作就不需要这条汇编)- 寄存器
rax的值与自身进行按位逻辑与操作,结果会影响处理器的标志位。 - 如果
rax的值为零(即nullptr),则进行 AND 操作后结果为零,"零标志位"(ZF,Zero Flag)会被设置为 1,表示相等。 - 如果
rax的值不为零(即指向有效内存),"零标志位"会被设置为 0,表示不相等。
- 寄存器
- 按位与:有0为0
- 按位或:有1为1
- 按位非:按位取反
- 按位异或:同0异1
|
1 |
test rax, rax |
- 根据 "零标志位" 的值来判断是否跳转到
.L2标签处- 如果 "零标志位" 为 1,即指针
pss为nullptr,则会执行跳转,否则不会执行跳转
- 如果 "零标志位" 为 1,即指针
|
1 |
je .L2 |
- delete操作对应代码
- 8传给参数1
rdi,表示要delete的内存的大小 rax存着new出来的堆区的内存的地址,把它传给参数2rdi- 然后调用delete操作
- 8传给参数1
|
1 2 3 |
mov esi, 8 mov rdi, rax call operator delete(void*, unsigned long) |
- 根据上面的分析,当
new出来的堆区内存的地址为nullptr时,je指令会跳转到标签.L2.L2是针对delete操作生成的- 将局部的pss置空
mov eax,0对应的是return 0;
leave- 用于恢复栈帧
- 等效于
mov rsp, rbp和pop rbp,将rbp恢复为原来的值,同时移动栈指针rsp以释放当前栈帧所使用的空间。这个操作将栈帧恢复到了调用该函数前的状态。
ret- 用于函数的返回。它从函数中跳出,将控制权返回给调用者
- 从栈中弹出返回地址(保存在调用函数时被压入的栈中),然后将程序计数器(PC)设置为该返回地址的值,从而实现函数的返回。
|
1 2 3 4 5 |
.L2: mov QWORD PTR [rbp-8], 0 mov eax, 0 leave ret |
- 返回地址
call指令会将下一条指令的地址(返回地址)压入栈中- 也就是说,在调用函数之前,调用函数的返回地址已经被压入栈中,以便被调用函数执行完毕后,能够通过
ret指令将控制权返回到调用函数的位置 - 而
ret指令,会从栈中弹出返回地址,然后跳转到该地址继续执行调用函数的下一条指令
|
1 |
call operator new(unsigned long) |
nop
代码
|
1 2 3 4 5 6 7 |
void test() { int i = 0; } void test() { // int i = 0; } |
汇编
|
1 2 3 4 5 6 7 |
test(): push rbp mov rbp, rsp mov DWORD PTR [rbp-4], 0 nop pop rbp ret |
|
1 2 3 4 5 6 |
test(): push rbp mov rbp, rsp nop pop rbp ret |
解析
- nop 指令通常被称为
"no operation"或"no-op"指令,它在汇编语言中没有任何操作,仅用于占位。 - 编译器在生成汇编代码时,可能会插入一些无操作指令,可能的原因如下:
- 编译器可能会为了代码对齐的目的插入
nop指令,以确保指令的起始地址是按照某个特定的对齐要求对齐的。对齐可以提高指令的执行效率。 - 在调试信息中,插入
nop指令可以帮助与源代码的行号信息对应,以便在调试时能够更准确地定位问题。 - 编译器可能在生成代码时使用一些通用的代码模板,其中包括一些
nop指令。这些模板可能在优化、调试或其他情况下被插入。
- 编译器可能会为了代码对齐的目的插入
空类
代码1
|
1 2 3 |
class a { public: }; |
代码2
|
1 2 3 4 5 |
class a { public: a() {} ~a() {} }; |
汇编
- 代码1不生成汇编代码
- 该对象没有成员变量或成员函数
- 也没有显示的构造函数或析构函数
- 在这种情况下,编译器可以推断出对象的构造函数和析构函数是空的,而且没有其他操作需要进行,因此可以将整个代码段进行优化,以减少生成的汇编代码
- 代码2汇编如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
a::a() [base object constructor]: push rbp mov rbp, rsp mov QWORD PTR [rbp-8], rdi nop pop rbp ret a::~a() [base object destructor]: push rbp mov rbp, rsp mov QWORD PTR [rbp-8], rdi nop pop rbp ret main: push rbp mov rbp, rsp push rbx sub rsp, 24 lea rax, [rbp-17] mov rdi, rax call a::a() [complete object constructor] mov ebx, 0 lea rax, [rbp-17] mov rdi, rax call a::~a() [complete object destructor] mov eax, ebx mov rbx, QWORD PTR [rbp-8] leave ret |
解析
- 创建堆栈,分配栈空间给局部对象和临时数据
- 这个代码里栈大小为什么是32个字节大小
push rbx,占了8个字节- 然后又从rsp的位置又分配了24个字节
- 对象a占1个字节,在
[rbp-17] - 至于说为什么计算到对象的地址在
[rbp-17]这里,从上面的代码里没看出来
|
1 2 3 4 |
push rbp mov rbp, rsp push rbx sub rsp, 24 |
- 计算对象a的地址
- 这个也是对象a的
this指针
- 这个也是对象a的
- 将
this指针作为第一个参数传递给成员函数(构造函数) - 在a的构造里面,也有创建新的堆栈的动作,不过新的堆栈的位置是在上面创建的32个字节的后面了
|
1 2 3 |
lea rax, [rbp-17] mov rdi, rax call a::a() [complete object constructor] |
ebx被用作一个临时变量,用来在 main 函数的退出处存储返回值- 为什么用
ebx,它是rbx低32位,可以将它赋值给同样是32位的eaxrax在上面接收了对象的地址(8个字节,64位),里面有数据- 而一般将
rax用作存储函数的返回值,所以需要让rax里面存储正确的返回值 - 但是呢,这里函数最后返回的是一个int,占32位,所以不用管
rax的高32位,只需清0rax的低32位,也就是只需设置eax为0即可
|
1 |
mov ebx, 0 |
- 将
this指针作为第一个参数传递给成员函数(析构函数)
|
1 2 3 |
lea rax, [rbp-17] mov rdi, rax call a::~a() [complete object destructor] |
- 将
ebx中的值(即 0)复制到eax中,从而将返回值设置为 0,以表示 main 函数的正常退出- 见上述,由于函数返回的是int,占32位,所以只需清0
eax即可
- 见上述,由于函数返回的是int,占32位,所以只需清0
|
1 |
mov eax, ebx |
- 这里为什么还有保存对象的地址
- 目的是为了确保在函数返回前能够访问对象的地址。
- 这是因为
a::~a()析构函数可能需要在函数返回之后继续使用对象的地址进行清理操作。 - 通过将对象地址保存在
rbx寄存器中,可以确保在函数返回后仍然能够访问对象的地址。
- 尽管在析构函数调用结束后,对象已经被销毁,但是编译器可能需要处理一些代码,比如清理栈帧、恢复寄存器等。
- 在这个过程中,对象的地址可能仍然需要使用,因此编译器选择将其保存在
rbx寄存器中,以备后续的可能需要。
|
1 |
mov rbx, QWORD PTR [rbp-8] |
leave指令用于恢复函数的栈帧。- 在函数开始时,通常会使用
push rbp将前一个函数的栈帧指针rbp压入栈中,然后通过mov rbp, rsp将当前栈指针rsp的值赋给栈帧指针rbp,建立一个新的栈帧。 leave指令的作用是撤销这些操作,它等效于以下两条指令:mov rsp, rbp:将栈指针rsp设置为栈帧指针rbp的值,这样恢复了栈指针的位置。pop rbp:从栈中弹出栈帧指针rbp,恢复前一个函数的栈帧指针。
|
1 2 |
leave ret |
本文为原创文章,版权归Aet所有,欢迎分享本文,转载请保留出处!

热评文章
- x86_64汇编学习记述二 0
- 标志寄存器 0
- X86_64汇编学习记述三 0
- 相关指令 0
- X86_64汇编学习记述四 0
- 定位内存与数据处理 0