
内存模型
对象和内存位置
- 在一个
C++程序中的所有数据都是由对象(objects)构成。 - 无论对象是怎么样的一个类型,一个对象都会存储在一个或多个内存位置上。
- 每一个内存位置不是一个标量类型的对象,就是一个标量类型的子对象,比如,
unsigned short,my_calss*或序列中的相邻位域。 - 当使用位域时,就需要注意:虽然相邻位域中是不同的对象,但仍视其为相同的内存位置。
- 如下图:
- 每一个内存位置不是一个标量类型的对象,就是一个标量类型的子对象,比如,
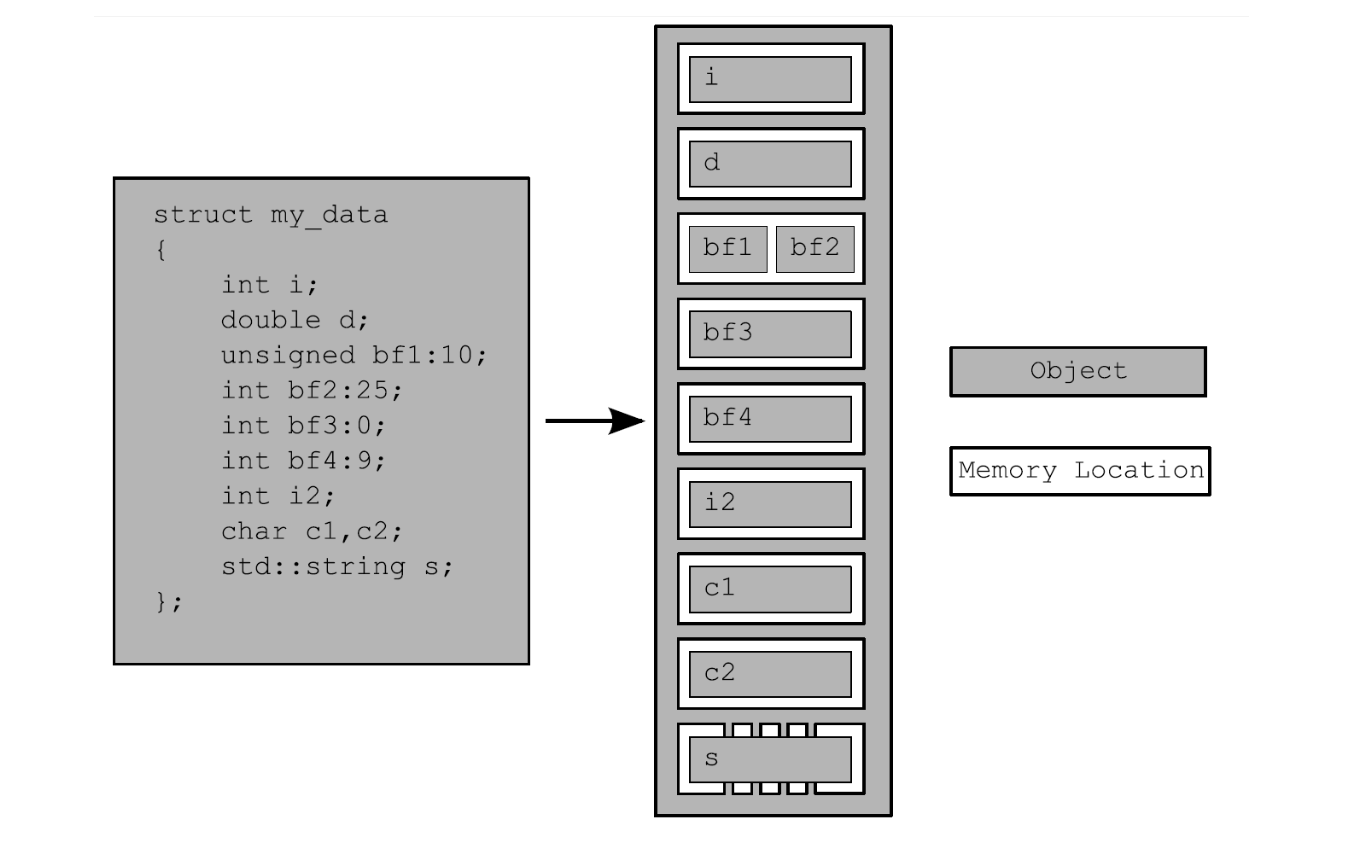
- 注意
- 每一个变量都是一个对象,包括作为其成员变量的对象
- 每个对象至少占有一个内存位置
- 基本类型都有确定的内存位置
- 相邻位域是相同内存中的一部分
内存位置和并发
-
所有东西都在内存中,当两个线程访问不同的内存位置时,不会存在任何问题;当两个线程访问同一个内存位置时,就需要小心了。如果没有线程更新内存位置上的数据,还好,只读数据不需要保护或同步,当有线程对内存位置上的数据进行修改,就有可能会产生条件竞争。
-
为了避免条件竞争,两个线程需要一定的执行顺序。
- 使用互斥量来确定访问的顺序
- 使用原子操作同步机制,决定两个线程的访问顺序
-
如果不去规定两个不同线程对同一内存地址访问的顺序,那么访问就不是原子的;并且,当两个线程都是“作者”时,就会产生数据竞争和未定义行为。
修改顺序
- 每一个在C++程序中的对象,都有(由程序中的所有线程对象)确定好的修改顺序,在初始化开始阶段确定。
- 在大多数情况下,这个顺序不同于执行中的顺序,但是在给定的执行程序中,所有线程都需要遵守这顺序。
- 当对象不是一个原子类型,就有必要确保有足够的同步操作,来确定每个线程都遵守了变量的修改顺序。
原子操作
- 原子操作是不可分割的操作。
标准原子类型
- 标准原子类型以及相关特化
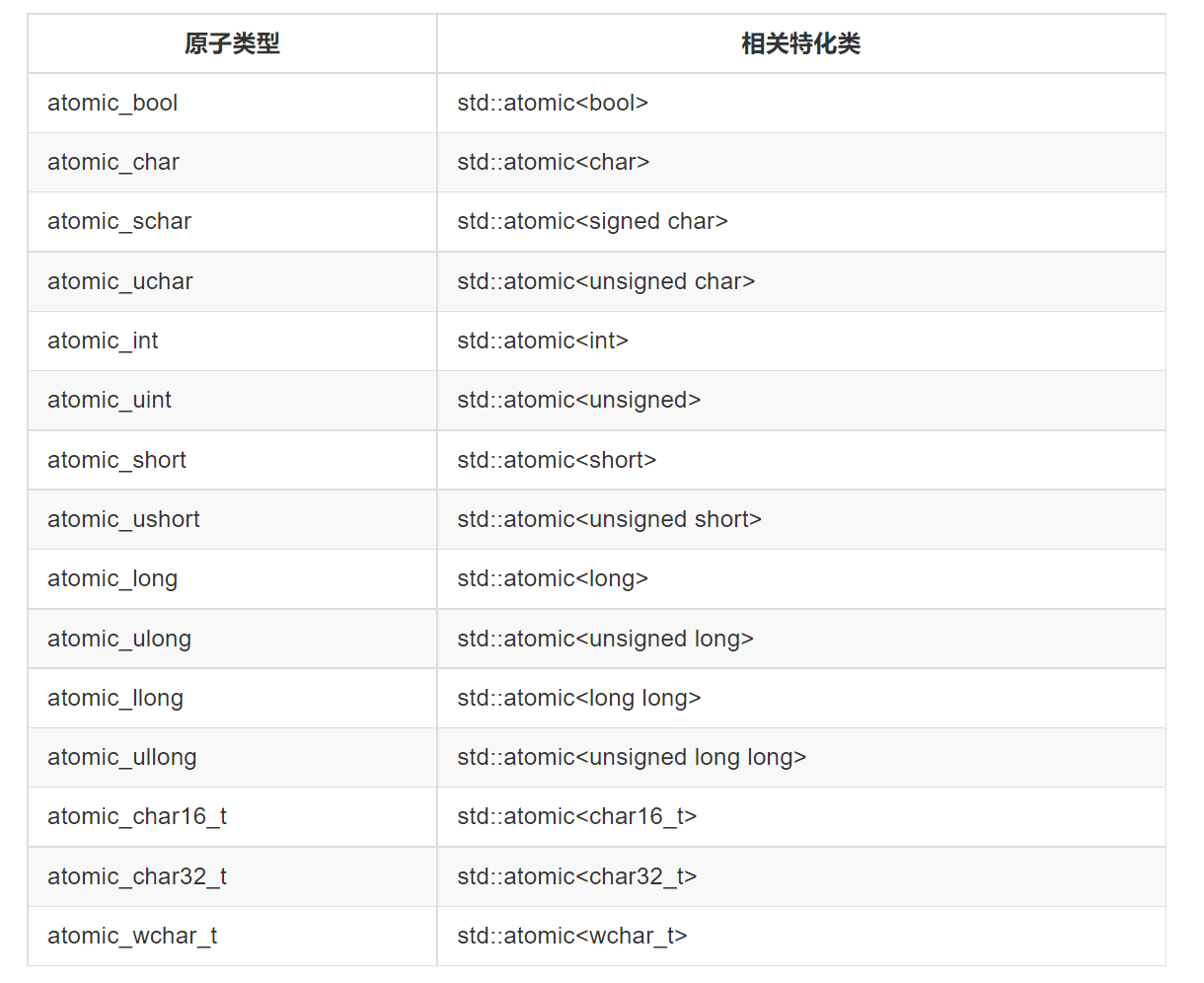
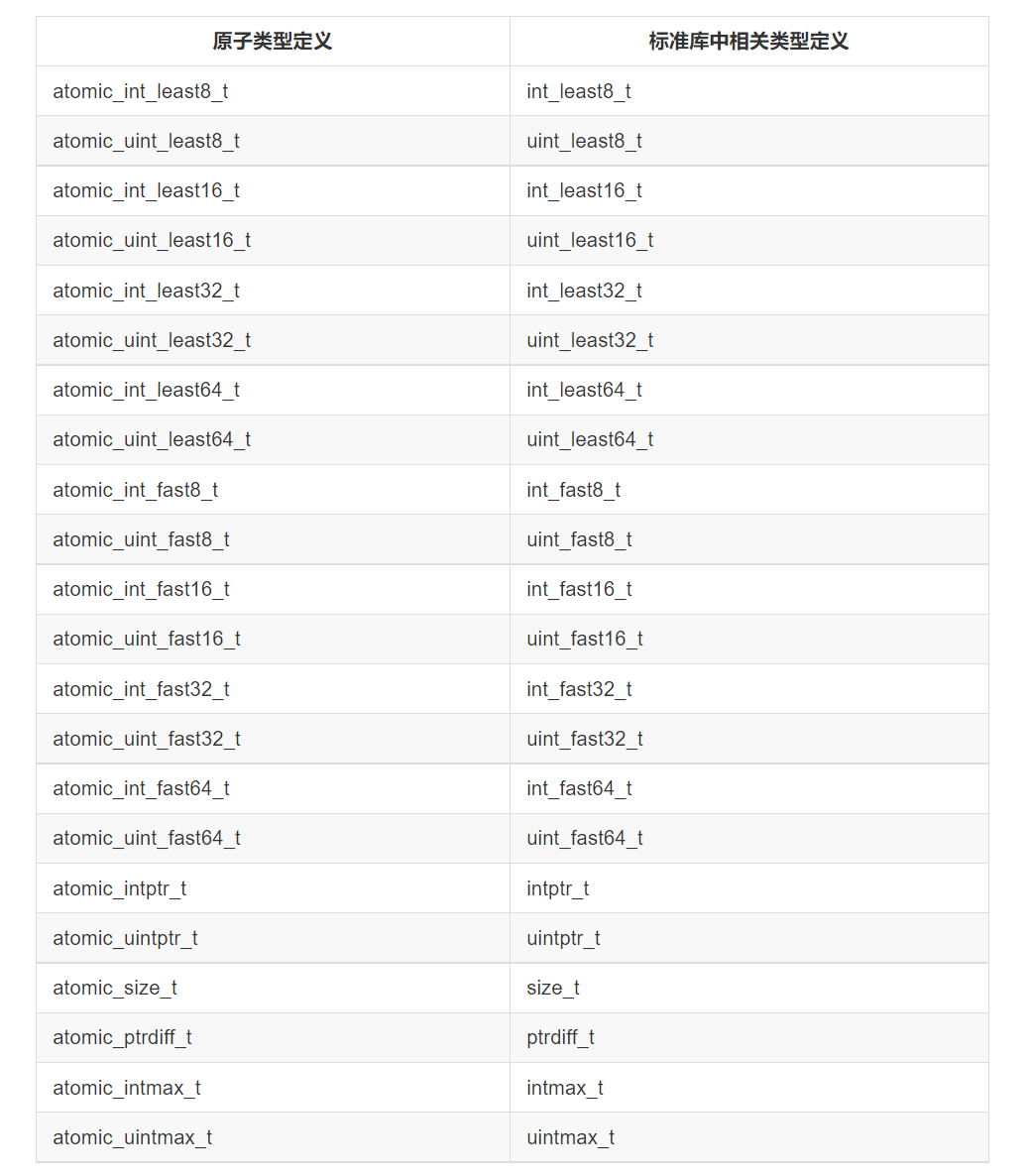
- 标准原子类型定义以及对应的内置类型定义
- 通常,标准原子类型是不能拷贝和赋值,他们没有拷贝构造函数和拷贝赋值操作。但是,因为可以隐式转化成对应的内置类型,所以这些类型依旧支持赋值,可以使用如下操作:
load():用于获取原子变量的值;保证原子性,确保在你读取值的时候,该值不会被其他线程修改store(T val):用于设置原子变量的值;保证在设置值的时候,该值不会被其他线程读取或修改exchange(T new_value):将原子变量设置为new_value,并返回变量以前的值compare_exchange_weak(T& expected, T new_value)compare_exchange_strong(T& expected, T new_value)- 上面这两个函数尝试将原子变量的值设置为
new_value,但只有在当前值等于expected时才这样做 - 如果操作成功,原子变量的值将被设置为
new_value,并返回true - 如果操作失败(即当前值不等于
expected),则不会修改原子变量,而是将expected设置为当前值,并返回false - 区别在于,
compare_exchange_weak可能会产生假负(即即使当前值等于expected,它也可能会返回false),因为它可能不会重试操作 - 而
compare_exchange_strong保证只要当前值等于expected,它就一直重试直到成功为止 - 执行比较-交换操作时可能会发生中断或缓存冲突,这种情况可能会导致上面这两个函数失败
- 每种函数类型的操作都有一个可选内存排序参数,这些参数可以用来指定所需存储的顺序,详细如下5,6,7条
- store
memory_order_relaxedmemory_order_releasememory_order_seq_cst
- load
memory_order_relaxedmemory_order_consumememory_order_acquirememory_order_seq_cst
- read-modify-write
memory_order_relaxedmemory_order_consumememory_order_acquirememory_order_releasememory_order_acq_relmemory_order_seq_cst
atomic_flag
- 这个类型的对象可以在两个状态间切换:设置和清除。
std::atomic_flag类型的对象必须被ATOMIC_FLAG_INIT初始化
它是唯一需要如此特殊的方式初始化的原子类型,但它也是唯一保证无锁的类型
|
1 |
std::atomic_flag f = ATOMIC_FLAG_INIT; |
- 当标志对象已经初始化,只能销毁,清除,或设置。
cleartest_and_set
自旋互斥锁
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class spinlock_mutex { std::atomic_flag flag; public: spinlock_mutex() : flag(ATOMIC_FLAG_INIT) { } void lock() { while(flag.test_and_set(std::memory_order_acquire)); } void unlock() { flag.clear(std::memory_order_release); } }; |
atomic
atomic<bool>
|
1 2 |
std::atomic<bool> b(true); b = false; |
|
1 2 3 4 |
std::atomic<bool> b; bool x=b.load(std::memory_order_acquire); b.store(true); x=b.exchange(false, std::memory_order_acq_rel); |
atomic指针运算
|
1 2 3 4 5 6 7 8 9 |
class Foo{}; Foo some_array[5]; std::atomic<Foo*> p(some_array); Foo* x=p.fetch_add(2); // p加2,并返回原始值 assert(x==some_array); assert(p.load()==&some_array[2]); x=(p-=1); // p减1,并返回原始值 assert(x==&some_array[1]); assert(p.load()==&some_array[1]); |
atomic主要类的模板
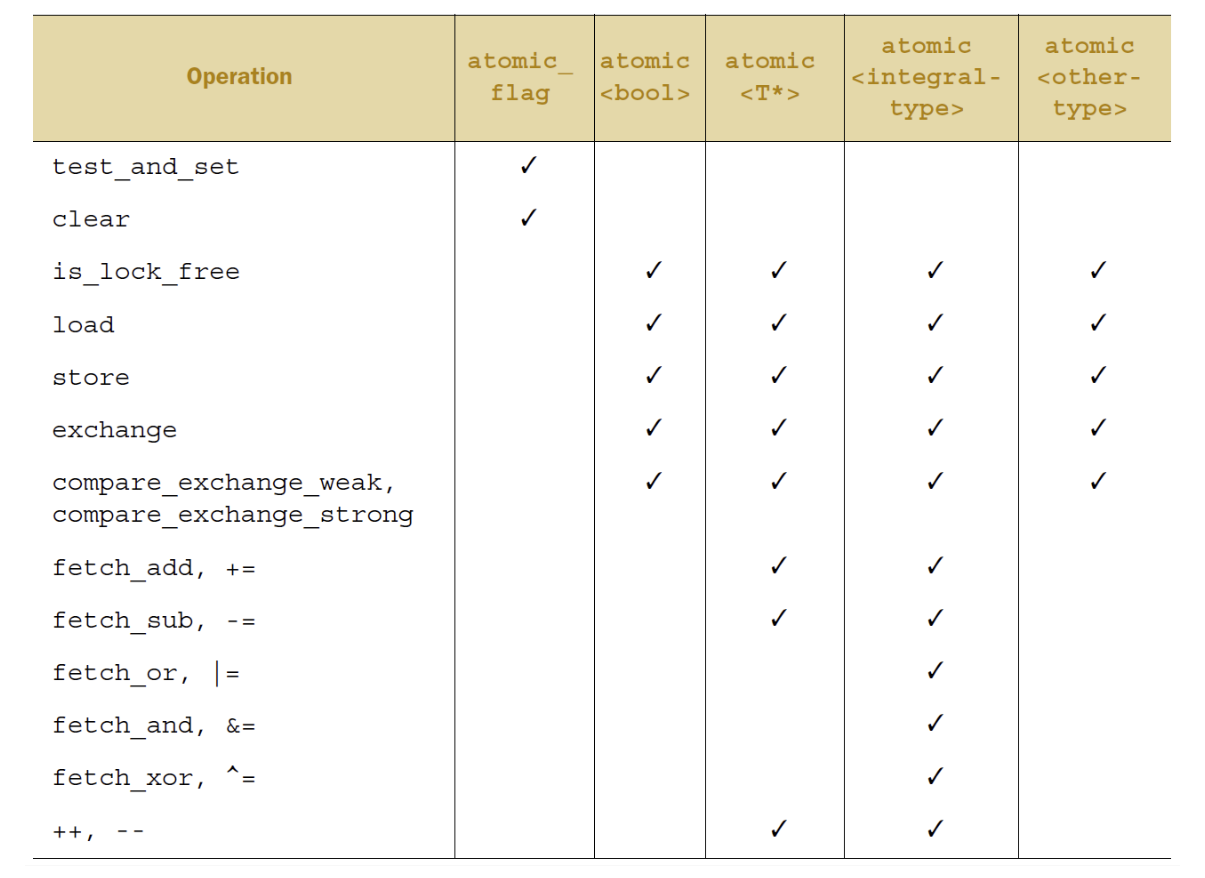
原子操作释放函数
|
1 2 3 4 5 6 7 8 9 10 11 |
std::shared_ptr<my_data> p; void process_global_data() { std::shared_ptr<my_data> local=std::atomic_load(&p); process_data(local); } void update_global_data() { std::shared_ptr<my_data> local(new my_data); std::atomic_store(&p,local); } |
同步操作
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <vector> #include <atomic> #include <iostream> std::vector<int> data; std::atomic<bool> data_ready(false); void reader_thread() { while(!data_ready.load()) { std::this_thread::sleep(std::milliseconds(1)); } std::cout << data[0] << std::endl; } void writer_thread() { data.push_back(42); data_ready = true; } |
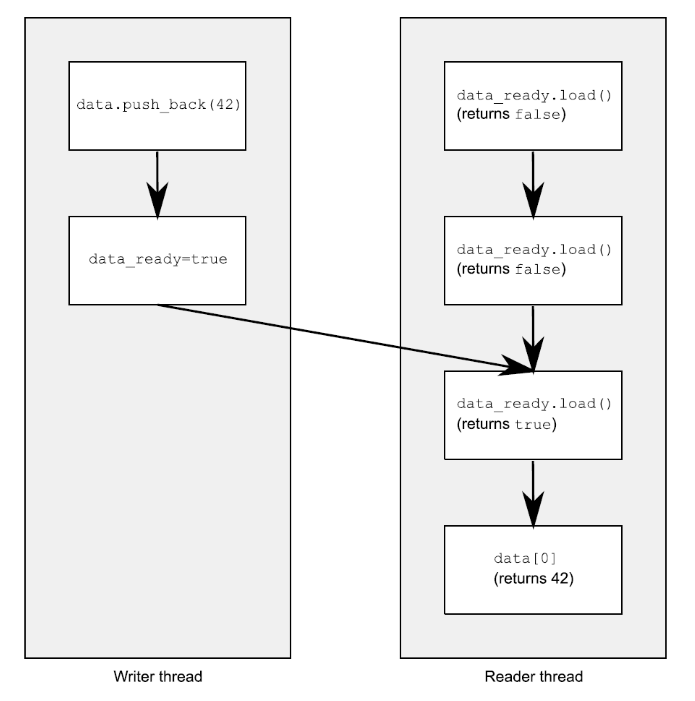
原子操作的内存顺序
memory_order_relaxedmemory_order_consumememory_order_acquirememory_order_releasememory_order_acq_relmemory_order_seq_cst
内存模型
- 虽然有六个内存序列选项,但是它们仅代表了三种内存模型,如下
- 排序一致序列
memory_order_seq_cst
- 获取-释放序列
memory_order_consumememory_order_acquirememory_order_releasememory_order_acq_rel
- 自由序列
memory_order_relaxed
排序一致队列
- 默认序列命名为排序一致,是因为程序中的行为从任意角度去看,序列顺序都保持一致。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
#include <atomic> #include <thread> #include <assert.h> std::atomic<bool> x,y; std::atomic<int> z; void write_x() { x.store(true, std::memory_order_seq_cst); } void write_y() { y.store(true, std::memory_order_seq_cst); } void read_x_then_y() { while(!x.load(std::memory_order_seq_cst)); if (y.load(std::memory_order_seq_cst)) { ++z; } } void read_y_then_x() { while(!y.load(std::memory_order_seq_cst)); if (x.load(std::memory_order_seq_cst)) { ++z; } } int main() { x = false; y = false; z = 0; std::thread a(write_x); std::thread b(write_y); std::thread c(read_x_then_y); std::thread d(read_y_then_x); a.join(); b.join(); c.join(); d.join(); assert(z.load()!=0); } |
非排序一致内存模型
- 当你踏出序列一致的世界,所有事情就开始变的复杂。可能最需要处理的问题就是:再也不会有全局的序列了。这就意味着不同线程看到相同操作,不一定有着相同的顺序,还有对于不同线程的操作,都会整齐的,一个接着另一个执行的想法是需要摒弃的。不仅是你有没有考虑事情真的同时发生的问题,还有线程没必要去保证一致性。
自由序列
- 在原子类型上的操作以自由序列执行,没有任何同步关系。在同一线程中对于同一变量的操作还是服从先发执行的关系,但是这里不同线程几乎不需要相对的顺序。
- 当使用memory_order_relaxed,就不需要任何额外的同步,对于每个变量的修改顺序只是线程间共享的事情。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#include <atomic> #include <thread> #include <assert.h> std::atomic<bool> x,y; std::atomic<int> z; void write_x_then_y() { x.store(true,std::memory_order_relaxed); // 1 y.store(true,std::memory_order_relaxed); // 2 } void read_y_then_x() { while(!y.load(std::memory_order_relaxed)); // 3 if(x.load(std::memory_order_relaxed)) // 4 ++z; } int main() { x=false; y=false; z=0; std::thread a(write_x_then_y); std::thread b(read_y_then_x); a.join(); b.join(); assert(z.load()!=0); // 5 } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
#include <thread> #include <atomic> #include <iostream> std::atomic<int> x(0),y(0),z(0); // 1 std::atomic<bool> go(false); // 2 unsigned const loop_count=10; struct read_values { int x,y,z; }; read_values values1[loop_count]; read_values values2[loop_count]; read_values values3[loop_count]; read_values values4[loop_count]; read_values values5[loop_count]; void increment(std::atomic<int>* var_to_inc,read_values* values) { while(!go) std::this_thread::yield(); // 3 自旋,等待信号 for(unsigned i=0;i<loop_count;++i) { values[i].x=x.load(std::memory_order_relaxed); values[i].y=y.load(std::memory_order_relaxed); values[i].z=z.load(std::memory_order_relaxed); var_to_inc->store(i+1,std::memory_order_relaxed); // 4 std::this_thread::yield(); } } void read_vals(read_values* values) { while(!go) std::this_thread::yield(); // 5 自旋,等待信号 for(unsigned i=0;i<loop_count;++i) { values[i].x=x.load(std::memory_order_relaxed); values[i].y=y.load(std::memory_order_relaxed); values[i].z=z.load(std::memory_order_relaxed); std::this_thread::yield(); } } void print(read_values* v) { for(unsigned i=0;i<loop_count;++i) { if(i) std::cout<<","; std::cout<<"("<<v[i].x<<","<<v[i].y<<","<<v[i].z<<")"; } std::cout<<std::endl; } int main() { std::thread t1(increment,&x,values1); std::thread t2(increment,&y,values2); std::thread t3(increment,&z,values3); std::thread t4(read_vals,values4); std::thread t5(read_vals,values5); go=true; // 6 开始执行主循环的信号 t5.join(); t4.join(); t3.join(); t2.join(); t1.join(); print(values1); // 7 打印最终结果 print(values2); print(values3); print(values4); print(values5); } |
获取-释放序列
- 这个序列是自由序列(relaxed ordering)的加强版;虽然操作依旧没有统一的顺序,但是在这个序列引入了同步。
- 在这种序列模型中,原子加载就是获取(acquire)操作(memory_order_acquire),原子存储就是释放(memory_order_release)操作,原子读-改-写操作(例如fetch_add()或exchange())在这里,不是“获取”,就是“释放”,或者两者兼有的操作(memory_order_acq_rel)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#include <atomic> #include <thread> #include <assert.h> std::atomic<bool> x,y; std::atomic<int> z; void write_x() { x.store(true,std::memory_order_release); } void write_y() { y.store(true,std::memory_order_release); } void read_x_then_y() { while(!x.load(std::memory_order_acquire)); if(y.load(std::memory_order_acquire)) // 1 ++z; } void read_y_then_x() { while(!y.load(std::memory_order_acquire)); if(x.load(std::memory_order_acquire)) ++z; } int main() { x=false; y=false; z=0; std::thread a(write_x); std::thread b(write_y); std::thread c(read_x_then_y); std::thread d(read_y_then_x); a.join(); b.join(); c.join(); d.join(); assert(z.load()!=0); // 3 } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#include <atomic> #include <thread> #include <assert.h> std::atomic<bool> x,y; std::atomic<int> z; void write_x_then_y() { x.store(true,std::memory_order_relaxed); // 1 y.store(true,std::memory_order_release); // 2 } void read_y_then_x() { while(!y.load(std::memory_order_acquire)); // 3 自旋,等待y被设置为true if(x.load(std::memory_order_relaxed)) // 4 ++z; } int main() { x=false; y=false; z=0; std::thread a(write_x_then_y); std::thread b(read_y_then_x); a.join(); b.join(); assert(z.load()!=0); // 5 } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
std::atomic<int> data[5]; std::atomic<bool> sync1(false),sync2(false); void thread_1() { data[0].store(42,std::memory_order_relaxed); data[1].store(97,std::memory_order_relaxed); data[2].store(17,std::memory_order_relaxed); data[3].store(-141,std::memory_order_relaxed); data[4].store(2003,std::memory_order_relaxed); sync1.store(true,std::memory_order_release); // 1.设置sync1 } void thread_2() { while(!sync1.load(std::memory_order_acquire)); // 2.直到sync1设置后,循环结束 sync2.store(true,std::memory_order_release); // 3.设置sync2 } void thread_3() { while(!sync2.load(std::memory_order_acquire)); // 4.直到sync1设置后,循环结束 assert(data[0].load(std::memory_order_relaxed)==42); assert(data[1].load(std::memory_order_relaxed)==97); assert(data[2].load(std::memory_order_relaxed)==17); assert(data[3].load(std::memory_order_relaxed)==-141); assert(data[4].load(std::memory_order_relaxed)==2003); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
std::atomic<int> sync(0); void thread_1() { // ... sync.store(1,std::memory_order_release); } void thread_2() { int expected=1; while(!sync.compare_exchange_strong(expected,2, std::memory_order_acq_rel)) expected=1; } void thread_3() { while(sync.load(std::memory_order_acquire)<2); // ... } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
struct X { int i; std::string s; }; std::atomic<X*> p; std::atomic<int> a; void create_x() { X* x=new X; x->i=42; x->s="hello"; a.store(99,std::memory_order_relaxed); // 1 p.store(x,std::memory_order_release); // 2 } void use_x() { X* x; while(!(x=p.load(std::memory_order_consume))) // 3 std::this_thread::sleep(std::chrono::microseconds(1)); assert(x->i==42); // 4 assert(x->s=="hello"); // 5 assert(a.load(std::memory_order_relaxed)==99); // 6 } int main() { std::thread t1(create_x); std::thread t2(use_x); t1.join(); t2.join(); } |
|
1 2 3 4 5 6 7 8 |
int global_data[]={ … }; std::atomic<int> index; void f() { int i=index.load(std::memory_order_consume); do_something_with(global_data[std::kill_dependency(i)]); } |
释放队列与同步
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#include <atomic> #include <thread> std::vector<int> queue_data; std::atomic<int> count; void populate_queue() { unsigned const number_of_items=20; queue_data.clear(); for(unsigned i=0;i<number_of_items;++i) { queue_data.push_back(i); } count.store(number_of_items,std::memory_order_release); // 1 初始化存储 } void consume_queue_items() { while(true) { int item_index; if((item_index=count.fetch_sub(1,std::memory_order_acquire))<=0) // 2 一个“读-改-写”操作 { wait_for_more_items(); // 3 等待更多元素 continue; } process(queue_data[item_index-1]); // 4 安全读取queue_data } } int main() { std::thread a(populate_queue); std::thread b(consume_queue_items); std::thread c(consume_queue_items); a.join(); b.join(); c.join(); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#include <atomic> #include <thread> #include <assert.h> std::atomic<bool> x,y; std::atomic<int> z; void write_x_then_y() { x.store(true,std::memory_order_relaxed); // 1 std::atomic_thread_fence(std::memory_order_release); // 2 y.store(true,std::memory_order_relaxed); // 3 } void read_y_then_x() { while(!y.load(std::memory_order_relaxed)); // 4 std::atomic_thread_fence(std::memory_order_acquire); // 5 if(x.load(std::memory_order_relaxed)) // 6 ++z; } int main() { x=false; y=false; z=0; std::thread a(write_x_then_y); std::thread b(read_y_then_x); a.join(); b.join(); assert(z.load()!=0); // 7 } |
原子操作对非原子的操作排序
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#include <atomic> #include <thread> #include <assert.h> bool x=false; // x现在是一个非原子变量 std::atomic<bool> y; std::atomic<int> z; void write_x_then_y() { x=true; // 1 在栅栏前存储x std::atomic_thread_fence(std::memory_order_release); y.store(true,std::memory_order_relaxed); // 2 在栅栏后存储y } void read_y_then_x() { while(!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待 std::atomic_thread_fence(std::memory_order_acquire); if(x) // 4 这里读取到的值,是#1中写入 ++z; } int main() { x=false; y=false; z=0; std::thread a(write_x_then_y); std::thread b(read_y_then_x); a.join(); b.join(); assert(z.load()!=0); // 5 断言将不会触发 } |
内存序介绍
memory_order_relaxed
- 这是最宽松的内存顺序
- 它只保证单个原子操作的原子性,而不保证任何排序关系。这意味着,在不同的处理器或线程上,原子变量的加载和存储操作可以在时间上重新排序
- 示例如下:
- 有可能线程
A先执行第二句,并且此时线程B还没有把1存到y里面,所以r1的值可能得到0 - 同理,加入线程
B也先执行了第二行,并且此时线程A还没有把1写到x里面,所以r2的值可能会是0
|
1 2 3 4 5 6 7 |
// 线程A x.store(1, std::memory_order_relaxed); r1 = y.load(std::memory_order_relaxed); // 线程B y.store(1, std::memory_order_relaxed); r2 = x.load(std::memory_order_relaxed); |
memory_order_release
- 当原子变量以这种顺序进行存储时,它会确保在这个存储操作之前的所有写入(在当前线程中)都对其他线程都是可见的,即不会在时间上被重新排序到存储操作之后
- 示例如下:
- 线程1首先将非原子整数设置为
42,然后用memory_order_release语义将原子整数x设置为1 - 而线程2在循环中使用
memory_order_acquire语义在等待x值为1 - 一旦线程2等待到了,那么在线程1将x设置为1之前,修改的其他数据,线程2拿到的都是修改后的数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
std::atomic<int> x(0), y(0); int data = 0; void thread1() { data = 42; // 非原子操作 x.store(1, std::memory_order_release); // 原子操作 } void thread2() { while (x.load(std::memory_order_acquire) != 1) { // 等待x被设置为1 } assert(data == 42); // 此断言不会失败 } |
- 假如线程A在写这个x,线程B和C在以同样的方式等待x的值变为1:
- 问题1:B和C谁会先等到
- 问题2:假如B先等到了,那么B拿到的data的值是42。此时C是在阻塞吗
- 问题3:C如果不是阻塞的话,C看到的data的值是不是42
- 答案1:答案是不确定。
在多线程编程中,无法确切预测或保证哪个线程会先执行或先完成某个操作
线程调度取决于操作系统、硬件和其他多种因素 - 答案2:当B首先观察到x为1时,C可能仍然在阻塞,也可能已经开始执行。
如答案1所述,先后取决于线程调度 - 答案3:如果线程A已经用
memory_order_release语义将x设置为1,并且在此之前将data设置为42,那么当线程C(或线程B)使用memory_order_acquire观察到x为1时,它们也将保证看到data的值为42 - 总结:换句话说,不管有多少个线程在等待x的值变成1,只要x的值真的变成1了,这些等待的线程会以不确定的先后顺序跳出上面那个循环,并且当执行到
assert这里的时候,它们看到的data的值都会是42
memory_order_seq_cst
- 这是最严格的内存顺序,也是std::atomic的默认顺序
- 它不仅保证了单个原子操作的顺序,还确保了所有线程中的原子操作都按照一个单一、全局的顺序来观察
- 这提供了很强的同步保证,但可能比其他内存顺序稍微慢一点
- 它是怎么做到,如下:
- 单线程中的顺序:
memory_order_seq_cst确保了原子操作之间的顺序不会改变- 也就是说,如果你在代码中先写入一个原子变量 A,然后写入一个原子变量 B,那么这两个写入的顺序不会发生改变
- 跨线程中的顺序:
- 对于跨多个线程的操作,
memory_order_seq_cst会创建一个单一、全局的顺序 - 这意味着,如果线程 1 在写入原子变量 A 之后写入原子变量 B,并且线程 2 观察到 B 的新值,那么线程 2 也必定会观察到 A 的新值
- 处理器并不是真的按照某种全局的顺序去执行这些操作,而是使用各种内部机制(例如栅栏指令、缓存一致性协议等)来确保操作对其他线程都按照某种一致的顺序可见
- 对于跨多个线程的操作,
memory_order_consume
- 这是一种比较特殊的内存顺序,主要用于确保后续操作可以看到此加载操作所读取的值
- 与
memory_order_acquire相比,它只确保与加载操作直接相关的后续操作可以看到加载的数据,而不是所有后续操作 - 在实际中,
memory_order_consume的使用可能会导致硬件和编译器的复杂性,因此经常建议使用memory_order_acquire代替 - 什么是数据依赖性:
- 线程B在A点读取指针p,然后在B点使用这个指针读取value。这里,B点的操作数据依赖于A点的操作,因为我们基于在A点读取的值来读取value
- 对于数据依赖性,memory_order_consume确保:如果在A点的读取操作看到了线程A的写入(例如,它读到了一个非nullptr的指针),那么在B点的操作必然能看到线程A对这个指针所指向的数据的写入(例如,它读到的value为42)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
struct Data { int value; }; Data* p = nullptr; // 线程A p = new Data(); p->value = 42; // 线程B Data* local = p; // A if (local) { int read_value = local->value; // B } |
- 上述代码使用
memory_order_consume来读取
|
1 2 3 4 |
Data* local = p.load(std::memory_order_consume); // A if (local) { int read_value = local->value; // B } |
memory_order_acquire
- 这确保在此加载操作之前的所有读写操作不会被重新排序到此加载操作之后
- 它常常用于锁或其他同步原语,确保在读取某个标志或锁状态之后的所有操作都可以看到标志或锁之前的相关状态或数据
memory_order_acq_rel
- 它是一个组合的内存序
- 它结合了
memory_order_acquire和memory_order_release的语义,确保既有acquire语义又有release语义
- 它结合了
- 当你执行一个
read-modify-write (RMW)操作时,memory_order_acq_rel确保这两个部分都被正确地顺序化- 例如
std::atomic::fetch_add()或std::atomic::compare_exchange_strong()
- 例如
Acquire语义- 确保在此
RMW操作之前的所有读/写都在此操作之前完成,并且其他线程可以看到这些读/写操作的效果
- 确保在此
Release语义- 确保此
RMW操作之后的所有读/写都在此操作之后完成,并且在此操作之前的写入对于在此操作之后执行的任何读取都是可见的
- 确保此
- 示例:
- 一个原子计数器,并且你想在增加计数器时确保看到的计数器值是最新的,并且其他线程可以看到你增加的值
|
1 2 3 4 5 6 7 8 |
std::atomic<int> counter; void increment_and_fetch() { int old_value = counter.load(std::memory_order_relaxed); while (!counter.compare_exchange_strong(old_value, old_value + 1, std::memory_order_acq_rel, std::memory_order_relaxed)); } |
本文为原创文章,版权归Aet所有,欢迎分享本文,转载请保留出处!

你可能也喜欢
- ♥ C++17_第三篇06/29
- ♥ C++并发编程_概念了解05/07
- ♥ Protobuf记述与使用01/24
- ♥ 深入理解C++11:C++11新特性解析与应用 二12/30
- ♥ macOs 解析mach-o05/11
- ♥ Soui二05/18