
多态
编译时多态
- 通过函数重载实现
运行时多态
- 多态性可以概括为“一个接口,多个方法”,程序运行时才决定调用哪个具象化函数。
- 多态通过虚函数实现,虚函数允许子类重新定义成员函数,而子类重写定义父类函数的做法叫做覆盖,
override。
虚函数相关
概念
- 虚函数机制用以支持一个有效率的“执行期”绑定。
虚函数指针
- 每个
class产生出一堆指向虚函数的指针,放在表格当中。这个表格被称为svirtual table。 - 每一个类对象被安插一个指针,指向相关的
virtual table,这个指针通常被称为vptr。 vptr的设定和重置,都由每个类的构造、析构以及拷贝赋值运算符自动完成。- 每一个类所关联的
type_info object也经由virtual table被指出来,通常放在表格的第一个slot。
虚函数表
- C++的多态是通过虚函数来实现的。有虚函数的类里,会分配一个用以存放虚函数指针的空间,这个虚函数指针指向虚函数表。而虚函数表里,存的的这个类的虚函数的地址。
构造可为虚?
- 虚函数对应一个虚函数表,如果构造是虚的,就需要通过虚函数表来调用,但是对象都还没实例化,根本没有内存空间,也就找不到虚函数表
- 构造函数不允许是虚函数,因为创建一个对象时我们总要明确指定对象的类型,而如果是虚的,具体的类型要在运行时才能确定
vptr是在是在构造调用后才确定,所以构造不能为虚
析构可为虚?
- 如果析构不为虚,通过调用析构来释放空间时,可能会导致内存泄漏
Vector和List
vector是一段连续的内存空间,是物理上的连续;而list底层是双向链表实现的,它的节点之间是通过指针来体现出逻辑上的连续,在内存分配上,不是连续的空间。vector由于是连续的内存,所以它支持随机访问,时间复杂度为O(1);而list则需要通过指针来遍历,时间复杂度是O(n)。vector是连续的空间,所以它插入删除元素,就可能需要元素移动拷贝等操作;list插入删除不涉及数据的激动,改变相关节点的后继或前驱指针的值即可。- 添加元素时,
vector由于涉及空间的重新分配,所以指向容器的迭代器、指针以及引用会全部失效;而list则全都不失效。 - 删除元素时,
vector是被删除元素之前的迭代器是有效;list删除元素的时候也是全都不失效。
左右值和引用
左值
- 存储在内存中,有明确存储地址(可寻址)的数据。
右值
- 可以提供数据值的数据(但不一定可寻址,例如存在寄存器中)
引用
- 很久之前的C++标准就有引用的概念,使用 "&" 表示。
- 但这种引用有不足的地方,正常的情况下只能操作C++的左值,无法对右值添加引用。
右值引用
- C++11引入的另一种引用方式,用 "&&" 表示。
- 和声明左值引用一样,右值引用也必须立即进行初始化操作,且只能使用右值进行初始化。
- 右值引用主要用于移动语义和完美转发。
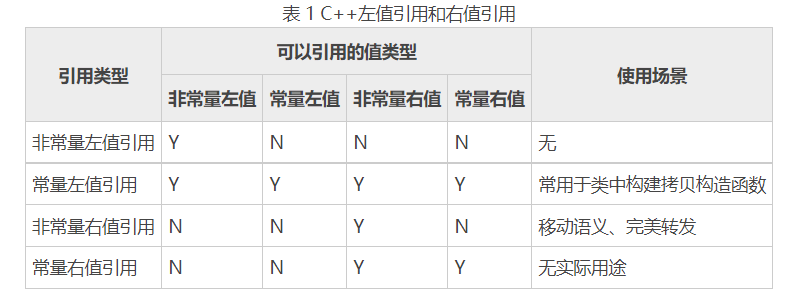
引用折叠
|
1 2 3 4 5 6 7 8 9 |
template<typename T> void f3(T &&) { //do something } //对于 int i = 22; f3(i); |
对于上面的代码,我们可能认为f3(i)这样的用法是不对的,毕竟,f的参数,需要的是一个右值,而我们给它的,却是一个左值,通常情况下,我们不能把一个右值引用绑定到一个左值上。
但是,C++语言在绑定规则之外,定义了两个例外规则,允许这种绑定的发生(而这两个例外规则是move这种标准库设施正确工作的基础):
- 当我们将一个左值(i)传递给函数的右值引用参数,且此右值引用指向模板类型参数(T&&)时,编译器推断模板类型参数为实参的左值引用类型。(因此,当我们调用f3(i)的时候,编译器推断T的类型为int&,而不是int)
- 如果我们间接创建一个引用的引用,则这些引用形成了”折叠“。
在除第一种例外的所有情况下,引用会折叠成一个普通的左值引用类型。
在C++11标准中,折叠规则扩展到右值引用。
只有一种情况下,引用会折叠成右值引用:右值引用的右值引用。
对于一个给定的X:
- X& &、X& &&、X&& &、都折叠成X&
- 类型X&& && 折叠成X&&
引用折叠只能应用于间接创建的引用的引用,如类型别名或函数模板。
如果将引用折叠和右值引用的特殊类型推断规则组合一起,则意味着我们可以对一个左值调用f3。
首位,编译器推断T为一个左值引用类型:
f3(i);//实参是一个左值,模板参数是int&
f3(i);//实参是一个左值,模板参数是const int &
当一个模板参数是T被推断为引用类型时,折叠规则告诉我们函数参数T&&折叠为一个左值引用类型。
|
1 2 |
//无效代码,用于参考 void f3<int&>(int& &&); |
f3的参数是T&&且T是int&,因此,T&&是int& &&,会折叠成int &。因此,即使f3的函数参数形式上是一个右值引用(T&&),此调用也会用一个左值引用类型(int&)实例化f3:
|
1 |
void f3<int&>(int&); |
这两个规则导致了两个重要的结果:
- 如果一个函数参数是一个指向模板类型参数的右值引用(T&&),则它可以被绑定到一个左值;且
- 如果实参是一个左值,则推断出的模板实参类型将是一个左值引用,且函数参数将被实例化为一个(普通)左值引用参数(T&)
std::move
|
1 2 3 4 |
template <class _Ty> _NODISCARD constexpr remove_reference_t<_Ty>&& move(_Ty&& _Arg) noexcept { // forward _Arg as movable return static_cast<remove_reference_t<_Ty>&&>(_Arg); } |
|
1 2 |
template <typename T> using remove_reference_t = typename std::remove_reference<T>::type; |
|
1 2 3 4 |
struct remove_reference { using type = _Ty; using _Const_thru_ref_type = const _Ty; }; |
select,poll,epoll区别
概述
- 上述select,poll和epoll都能同时监听多个文件描述符。它们将等待由timeout参数指定的超时时间,直到一个或多个文件描述符上有事件发生时,返回值是就绪的文件描述符的数量。返回0表示没有事件发生。
- 这3个函数都通过某种结构体变量来告诉内核监听哪些文件描述符上的哪些事件,并使用该结构体类型的参数来获取内核处理的结果。
Select
- select的参数类型fd_set没有将文件描述符和事件绑定,它仅仅是一个文件描述符集合,因此select还需要提供3个这种类型的参数来分别传入和输出可读、可写或异常等事件。
- 这一方面使得select不能处理更多类型的事件,另一方面由于内核对fd_set集合的在线修改,应用程序下次调用select前不得不重置这3个fd_set集合。
Poll
- poll的参数类型pollfd更“聪明”一些。因为它把文件描述符和事件都定义在结构体当中了,任何事件都被统一处理,从而使得编程接口简洁得多。
- 并且内核每次修改的都是pollfd结构体的revents成员,而events成员保持不变,因此下次调用poll时应用程序无须重置pollfd类型的事件集参数。
- 由于每次select和poll调用都返回整个用户注册的事件集合(其中包括就绪的未就绪的),所以应用程序索引就绪文件描述符的时间复杂度为O(n)。
Epoll
- epoll则采用了与select和poll完全不同的方式来管理用户注册的事件。它在内核中维护一个事件表,并提供了一个独立的系统调用epoll_ctl来控制往其中添加、删除、修改事件。
- 这样,每次epoll_wait调用都直接从该内核事件表中取得用户注册的事件,而无须反复从用户空间读入这些事件。
- epoll_wait系统调用的events参数仅用来返回就绪的事件,这使得应用程序索引就绪文件描述符的时间复杂度达到了O(1)。
综合
- poll和epoll_wait分别用nfds和maxevents参数指定最多监听多少个文件描述符和事件。
这两个数值都能达到系统允许打开的最大文件描述符数目,即65535个(cat/proc/sys/filemax)。
而select允许监听的最大文件描述符数量通常有限制,虽然用户可以修改这个限制,但可能会导致不可预期的后果。 - select和poll都只能工作在效率相对较低的LT模式,而epoll可以工作在效率较高的ET模式。
并且epoll还支持EPOLLONESHOT事件,该事件能进一步减少可读、可写和异常等事件被触发的次数。 - 从实现原理上来讲:
- select和epoll都是轮询的方式,即每次调用都要扫描整个注册文件描述符集合,并且将其中就绪的文件描述符返回给用户程序,因此它们检测就绪事件的算法的时间复杂度是O(n)。
- epoll_wait则不同,它采用的是回调的方式。内核检测到就绪的文件描述符时,将触发回调函数,回调函数就将该文件描述符上对应的事件插入内核就绪事件队列。
内核最后在适当的时机将该就绪事件队列中的内容拷贝到用户空间。
因此epoll_wait无须轮询整个文件描述符集合来检测哪些事件已就绪,其算法时间复杂度是O(1)。
- 需要注意的是,当活动连接比较多时,epoll_wait的效率未必比select和poll高,因为此时回调函数被触发得过于频繁。
所以epoll_wait适用于连接数量多,但活动连接较少的情况。
iocp
Windows消息处理相关
消息
- 消息(Message)指的就是Windows 操作系统发给应用程序的一个通告,它告诉应用程序某个特定的事件发生了。
- 从数据结构的角度来说,消息是一个结构体,它包含了消息的类型标识符以及其他的一些附加信息。
|
1 2 3 4 5 6 7 8 |
typedef struct tagMSG { HWND hwnd;//hwnd 是窗口的句柄,这个参数将决定由哪个窗口过程函数对消息进行处理 UINT message;//message是一个消息常量,用来表示消息的类型 WPARAM wParam;//wParam 和lParam 都是32 位的附加信息,具体表示什么内容,要视消息的类型而定 LPARAM lParam; DWORD time;//time 是消息发送的时间 POINT pt;//pt 是消息发送时鼠标所在的位置。 } MSG; |
消息队列
- Windows 系统中有两种消息队列
- 一种是系统消息队列
- 另一种是应用程序消息队列
- 计算机的所有输入设备由 Windows 监控,当一个事件发生时,Windows 先将输入的消息放入系统消息队列中,然后再将输入的消息拷贝到相应的应用程序的消息队列中,而应用程序中的消息循环则从程序的消息队列中检索每一个消息并发送给相应的窗口函数。
- Windows 操作系统为每个线程维持一个消息队列(对于没有消息循环的窗口,当该窗口收到消息时,系统会为它创建消息循环)。
- 当事件产生时,操作系统感知这一事件的发生,并包装成消息发送到消息队列,应用程序通过
GetMessage()函数取得消息并存于一个消息结构体中,然后通过一个TranslateMessage()和DispatchMessage()解释和分发消息
|
1 2 3 4 5 |
//Windows消息循环 while(GetMessage(&msg,NULL,0,0)) { TranslateMessage(&msg); DispatchMessage(&msg); } |
TranslateMessage(&msg)对于大多数消息而言不起作用,但是有些消息,比如键盘按键按下和弹起(分别对于KeyDown和KeyUp消息),却需要通过它解释,产生一个WM_CHAR消息。DispatchMessage(&msg)负责把消息分发到消息结构体中对应的窗口,交由窗口过程函数处理。GetMessage()在取得WM_QUIT之前的返回值都为TRUE,也就是说只有获取到WM_QUIT消息才返回FALSE,才能跳出消息循环。
消息循环
-
消息循环是Windows 应用程序存在的根本,应用程序通过消息循环获取各种消息,并通过相应的窗口过程函数,对消息加以处理。
正是这个消息循环使得一个应用程序能够响应外部的各种事件,所以消息循环往往是一个Windows 应用程序的核心部分。
|
1 2 3 4 5 |
//Windows消息循环 while(GetMessage(&msg,NULL,0,0)) { TranslateMessage(&msg); DispatchMessage(&msg); } |
消息处理
- 取得的消息将交由窗口处理函数进行处理,对于每个窗口类Windows为我们预备了一个默认的窗口过程处理函数
DefWindowProc(),这样做的好处是,我们可以着眼于我们感兴趣的消息,把其他不感兴趣的消息传递给默认窗口过程函数进行处理。 - 每一个窗口类都有一个窗口过程函数,此函数是一个回调函数,它是由Windows操作系统负责调用的,而应用程序本身不能调用它。以switch语句开始,对于每条感兴趣的消息都以一个case引出。default这个分支就会调用DefWindowProc。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
LRESULT CALLBACK WndProc ( HWND hwnd, UINT message, WPARAM wParam, LPARAM lParam ) { //... switch(uMsgId) { case WM_TIMER://对定时器消息处理 //... return 0; case WM_LBUTTONDOWN://对鼠标左键单击消息的处理 //... return 0; default: return DefWindowProc(hwnd,uMsgId,wParam,lParam); } } |
- 对于每条已经处理过的消息都必须返回0,否则消息将不停的重试下去;对于不感兴趣的消息,交给DefWindowProc()函数进行处理,并需要返回其处理值。
Socket相关
TCP服务端的创建过程
- 创建socket版本并启用socket环境
- 创建socket
- 绑定端口bind
- 监听网络端口listen
- 等待客户端连接accept
- 接收请求recv
- 回复请求send
TCP客户端的创建过程
- 创建socket版本并启用socket环境
- 创建socket
- 连接服务器connect
- 接收回复rescv
Soui位置
- pos属性可以指定4个值,也可以指定2个值。
- 指定4个值时,分别代表控件的left,top,right,bottom
- 指定两个值时代表控件的x,y,具体位置还依赖于另外3个参数。
- 指定4个值时,pos目前支持7种标志:|,%,[,],{,},@
- “|”代表参考父窗口的中心;如|-10代表在父窗口的中心向左/上偏移10象素。
- “%”代表在父窗口的百分比,可以是小数,负数。如:%40代表在父窗口的40%位置,%-40则等价于(1-40%)。
- “[”相对于前一兄弟窗口。用于X时,参考前一兄弟窗口的right,用于Y时参考前一兄弟窗口的bottom
- “]”相对于后一兄弟窗口。用于X时,参考后一兄弟的left,用于Y时参考后一兄弟的top
- “{”相对于前一兄弟窗口。用于X时,参考前一兄弟窗口的left,用于Y时参考前一兄弟窗口的top
- “}”相对于后一兄弟窗口。用于X时,参考后一兄弟的right,用于Y时参考后一兄弟的bottom
- “@”标志用来指定窗口的大小,只能出现在pos属性的第3,4个值中,用来标识窗口的宽度。当后面的值为负时,代表自动计算窗口的宽度或者高度
GetMessage和PeekMessage
PeekMessage在处理获得消息时候和GetMessage一样,关键不同的是PeekMessage在没有消息处理的时候还会继续保持循环激活状态,并且继续占用资源。GetMessage每次都会等待消息,直到取到消息才会返回。PeekMessage只是查询消息队列,没有消息就立即返回,从返回值判断是否取到了消息。GetMessage从消息队列中取不到消息,则线程就会被操作系统挂起,等待 OS 重新调度该线程;而PeekMessage线程会得到 CPU 的控制权,运行一段时间。GetMessage是从消息队列中“取出”消息,就把消息从消息队列中删除;PeekMessage的主要功能是“窥视”消息,如果有消息,就返回true,否则返回false。另外,也可以使用PeekMessage从消息队列中取出消息,这个功能涉及到它的一个参数(UINT wRemoveMsg),如果设置为PM_REMOVE,消息则被取出并从消息队列中删除;如果设置为PM_NOREMOVE,消息就不会从消息队列中取出。
SendMessage和PostMessage
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
LRESULT SendMessage( HWND hWnd, UINT Msg, WPARAM wParam, LPARAM lParam ); BOOL PostMessage( HWND hWnd, UINT Msg, WPARAM wParam, LPARAM lParam ); |
- sendmessage是同步的。
postmessage是异步的。 - sendmessage它等待消息被处理完了才返回,如果消息不被处理,发送消息的线程讲一直被阻塞。
postmessage只把消息放入队列,不管消息是否被处理就返回。 - 如果在同一个线程内,sendmessage发送消息时,由USER32.DLL模块调用目标窗口的消息处理程序,并将结果返回。sendmessage在同一线程中发送消息并不入线程消息队列。postmessage发消息时,消息要先放入线程的消息队列,然后通过消息循环分派到目标窗口。
- 如果在不同的线程内,sendmessage发送消息到目标窗口所属线程的消息队列,然后发送消息的线程在USER32.DLL模块内监视和等待消息处理,直到目标窗口处理完返回。
堆和栈相关
区别
- 堆
- 程序在运行期间用malloc或new申请的内存就是从堆区分配的。
- 一般来说,new分配的变量是存放于堆内存中的,但是返回的指针变量是存放在栈中的。
- 栈
- 由编译器自动分配释放,存放函数的参数值,局部变量等。
Linux进程空间分配情况

进程的栈
- Windows下:
- 一个进程栈默认大小是1M,但可以在VS的编译属性里面修改程序运行时进程栈的大小。
- Linux下:
- 进程栈默认大小是10M,可以通过
ulimit -s查看并修改默认栈大小。
- 进程栈默认大小是10M,可以通过
进程的堆
- 进程堆的大小理论上大概等于进程虚拟空间大小-内核虚拟内存大小。
- Windows,进程的高位2G留给内核,低位2G留给用户,所以进程堆的大小小于2G。
- Linux下,进程的高位1G留给内核,地位3G留给用户,所以进程堆大小小于3G。
进程的最大线程数
- 32位Windows下:
- 一个进程空间4G,内核占2G,留给用户2G,一个线程默认栈是1M,所以一个进程最大开2048个线程。
- 当然内存不会完全拿来做线程的栈,所以最大线程数实际是小于2048的,大概是2000个左右。
- 32位Linux下:
- 一个进程空间4G,内核占1G,留给用户3G,一个线程默认8M,所以最多是380左右个线程。
- 可以用
ulimit -a查看电脑最大进程数,大概7000多个。
本文为原创文章,版权归Aet所有,欢迎分享本文,转载请保留出处!

你可能也喜欢
- ♥ 2023_02_2202/27
- ♥ 2022_03_1403/17
- ♥ 2020_04_2905/01
- ♥ 后端知识点记述 一09/08
- ♥ 2025_03_1803/18
- ♥ 2023_02_2703/06
热评文章
- 2025_03_11 0
- 2020_04_29 0
- 2022_02_26 0
- 2025_03_18 0
- 2020_04_28 0
- 2022_03_09 0