
1-邻接矩阵
- 图的邻接矩阵存储方式是用两个数组来表示图。
- 一个一维数组存储图中的顶点信息。
- 一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
- 设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
$$
arc[i][j] =
\begin{cases}
1, \qquad 若(v_i,v_j)\in E 或<v_i,v_j> \in E \\
0, \qquad 反之
\end{cases}
$$
- 由上述算式,无向图的边数组是一个对称矩阵
- 某个顶点的度,就是这个顶点$v_i$在邻接矩阵中第i行(或第i列)的元素之和。
- 顶点$v_i$的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1,就是邻接点。
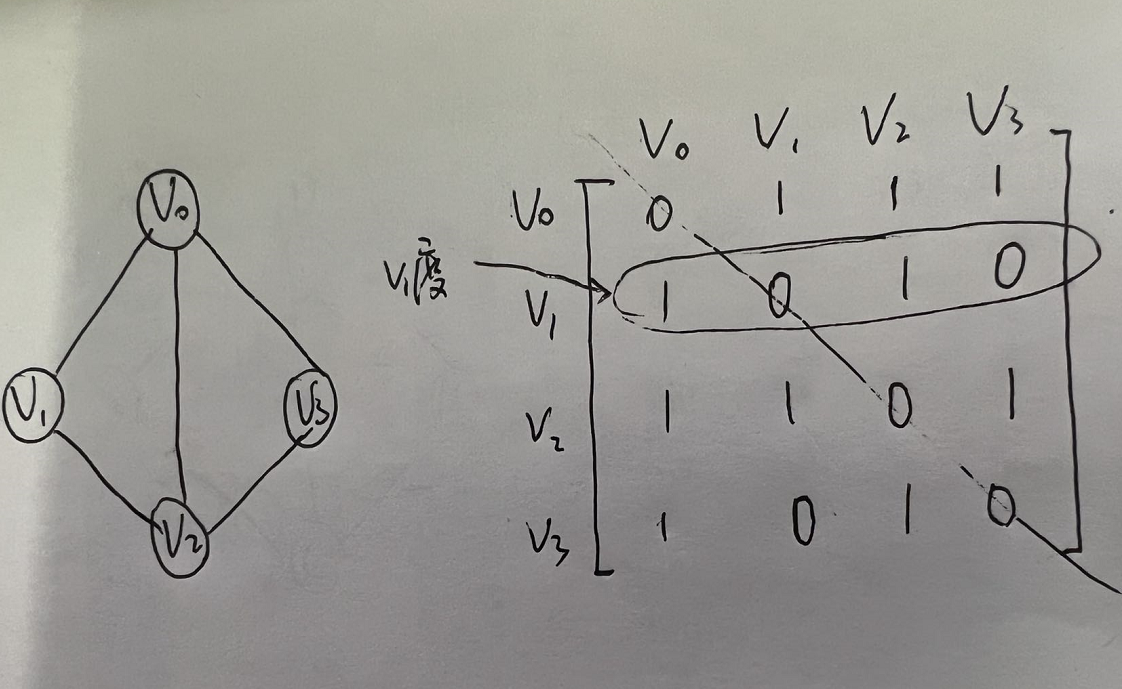
- 对于有向图:
- 判断顶点$v_i$和$v_j$是否存在弧,只需要查找矩阵中arc[i][j]是否为1即可。
- $v_i$的所有邻接点就是将矩阵第i行元素扫描一遍,查找arc[i][j]为1的顶点。
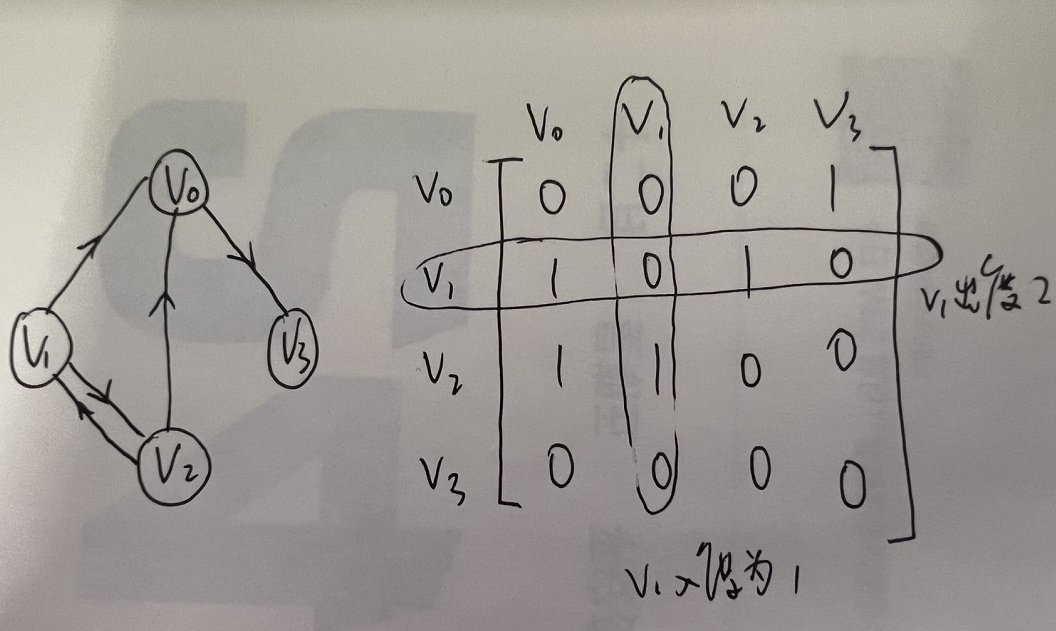
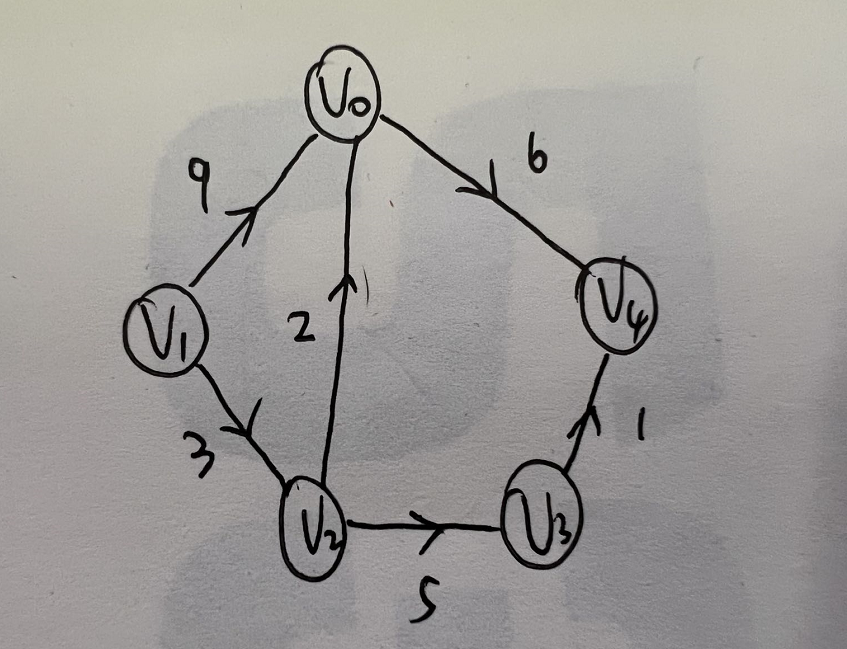
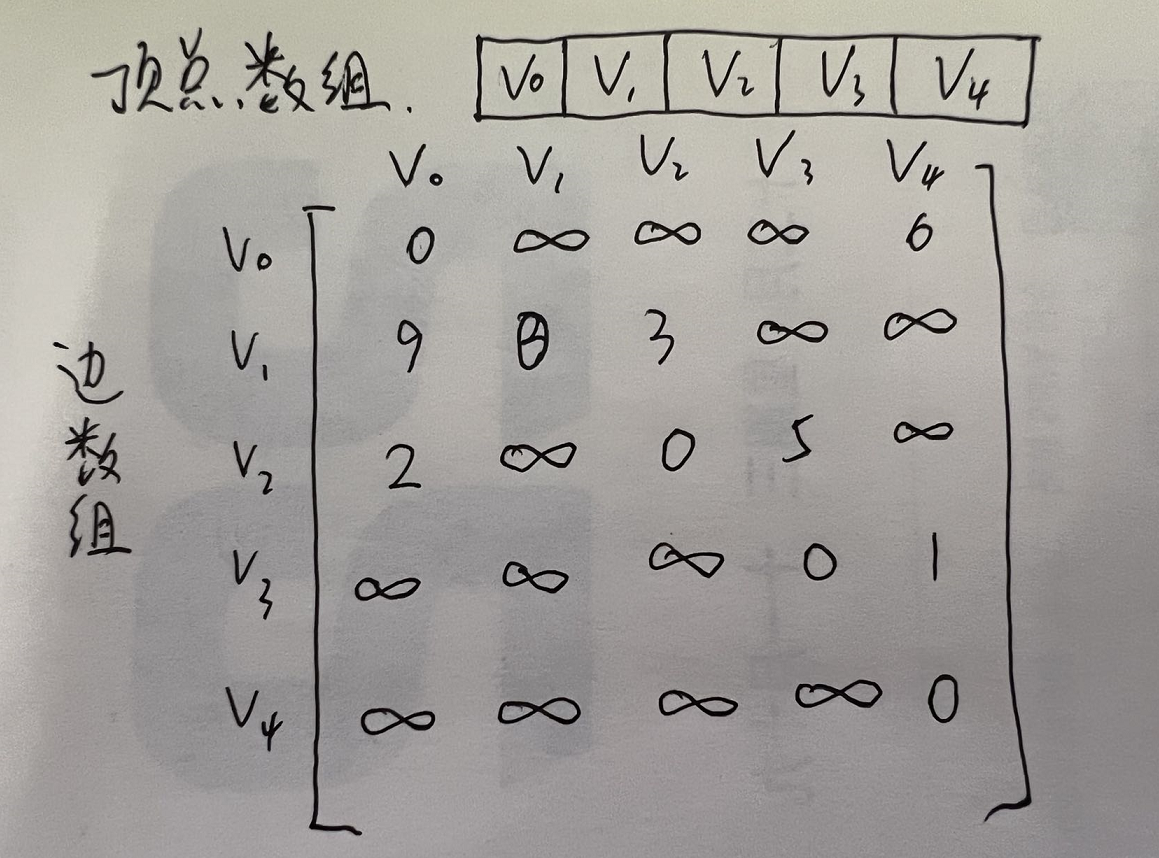
网图
- 设图G是网图,有n个顶点,则邻接矩阵是一个n*n的方阵,定义如下:
$$
arc[i][j] = \begin{cases}
W_{ij}, \qquad 若(v_i,v_j) \in E 或 <v_i, v_j> \in E \\
0, \qquad 若i = j \\
\infty, \qquad 反之
\end{cases}
$$
- $w_{ij}$表示$(v_i,v_j)$或$<v_i, v_j>$上的权值。
- $\infty$表示一个计算机允许的、大于所有边上的权值的值,也就是一个不可能的极限值。
邻接矩阵创建
|
1 2 3 4 5 6 7 8 9 10 |
typedef char VertexType; typedef int EdgeType; #define MAXVEX 100 #define INIINTY 65535 typedef strcut { VertexType vexs[MAXVEX]; EdgeType arc[MAXVEX][MAXVEX]; int numVertexes, numEdges; } MGraph; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
// 建立无向网图的邻接矩阵 void CreateMGraph(MGraph* G) { int i,j,k,w; printf("输入顶点和边数:"); scanf("%d,%d",&G->numVertexes, &G->numEdges); for (i = 0; i < G->numVertexes; i++) { scanf(&G->vexs[i]); } for (i = 0; i < G->numVertexes; i++) { for (j = 0; j < G->numVertexes; j++) { G->arc[i][j] = INFINITY; for (k = 0; k < G->numEdges; k++) { printf("输入边(v_i,v_j)上的下标i,下标j和权w:\n"); scanf("%d,%d,%d",&i,&j,&w); G->arc[i][j] = w; // 因为是无向图,所以矩阵对称 G->arc[i][j] = G->arc[i][j]; } } } } |
2-邻接表
- 邻接矩阵是一种还不错的图存储结构,但是对于边数相对顶点较少的图,这种结构是存在对存储空间的极大浪费的。
- 邻接表:
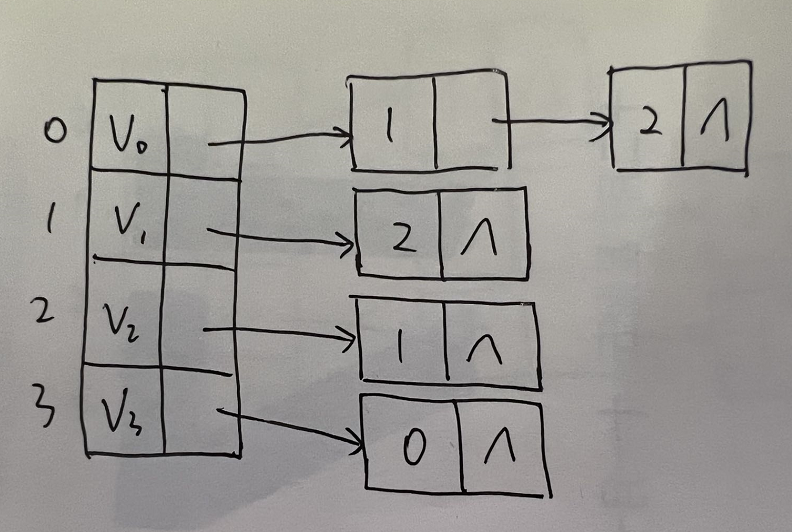
- 图中顶点用一个一维数组存储(也可以用单链表存储)。对于顶点数组中,每个数据元素还需要存储一个指向第一个邻接点的指针,以便于查找该顶点的信息。
- 图中每个顶点$v_i$的所有邻接点构成一个线性表,由于邻接点的个数不定,所有用单链表存储,无向图称为顶点$v_i$的边表,有向图则称为顶点$v_i$作为弧尾的出边表。
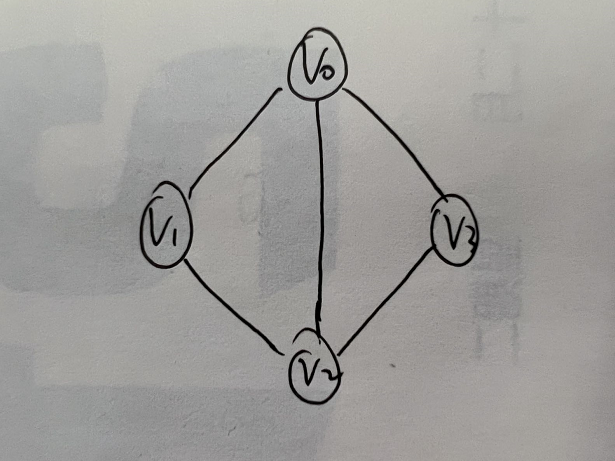
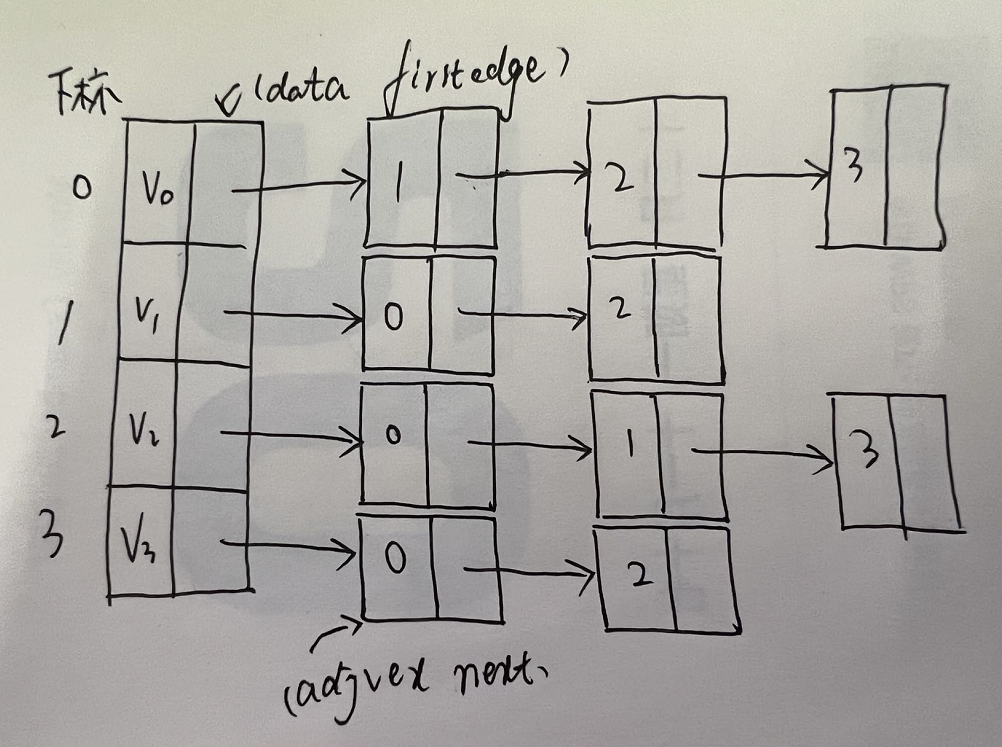
- 从上图,顶点表的各个结点是由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点。即此顶点的第一个邻接点。
- 边表是由adjvex和next两个域组成,adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。
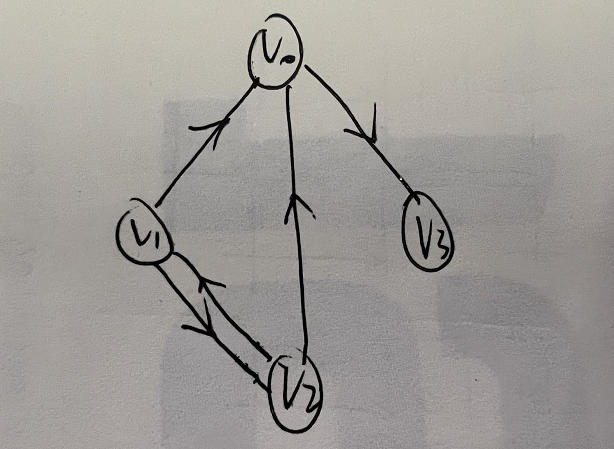
邻接表:
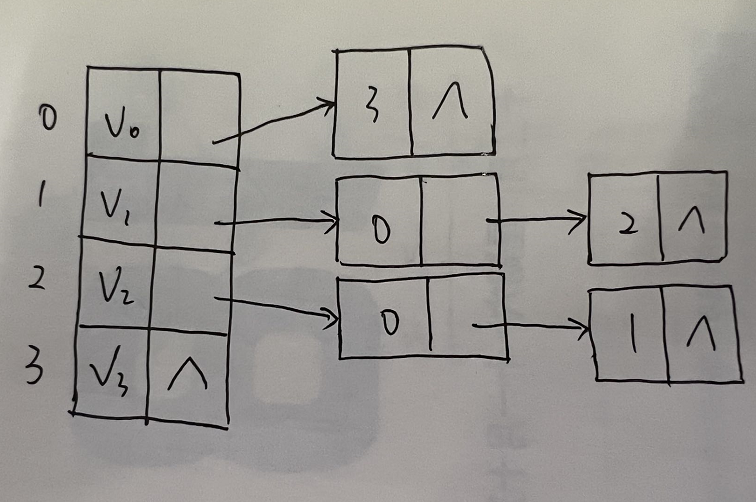
逆邻接表:
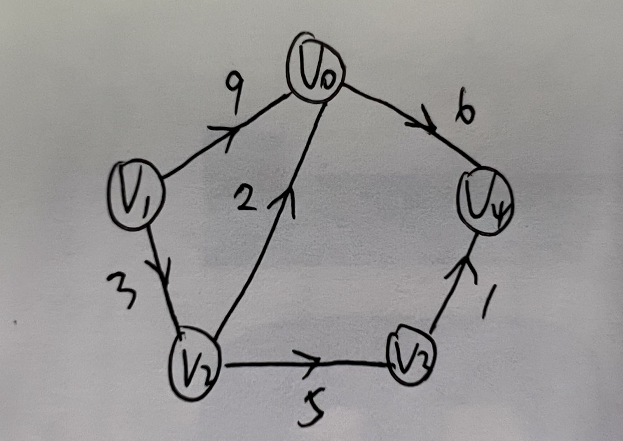
带权网图:
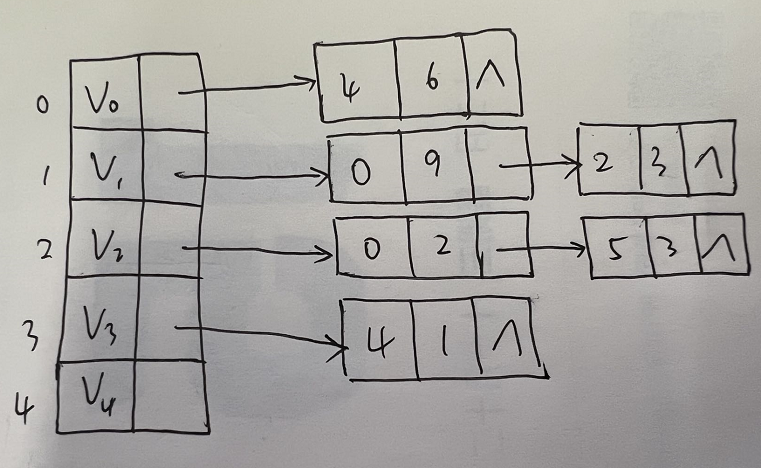
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
typedef char VertexType; typedef int EdgeType; typedef struct EdgeNode { int adgvex; EdgeType weight; struct EdgeNode* next; } EdgeNode; typedef struct VertexNode { VertexType data; EdgeNode* firstedge; } VertexNode, AdjList[MAXVEX]; typedef struct { AdjList adjList; int numVertexes, numEdges; } GraphAdjList; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
void CreateALGraph(GraphAdjList* G) { int i,j,k; EdgeNode* e; printf("输入顶点和边数\n"); scanf("%d,%d",&G->numVertexes, &G->numEdges); for (i = 0; i < G->numVertexes; i++) { scanf(&G->adjList[i].data); G->adjList[i].firstedge = NULL; } for (k = 0; k < G->numEdges; k++) { printf("输入边(v_i,v_j)上的顶点序号:\n"); scanf("%d,%d",&i,&j); e = (EdgeNode*)malloc(sizeof (EdgeNode)); e->adjvex = j; e->next=G->adjList[i].firstedge; G->adjList[i].firstedge = e; e = (EdgeNode*)malloc(sizeof (EdgeNode)); e->adjvex = i; e->next=G->adjList[i].firstedge; G->adjList[j].firstedge = e; } } |
3-十字链表
- 将邻接表和逆邻接表结合起来,就是十字链表。
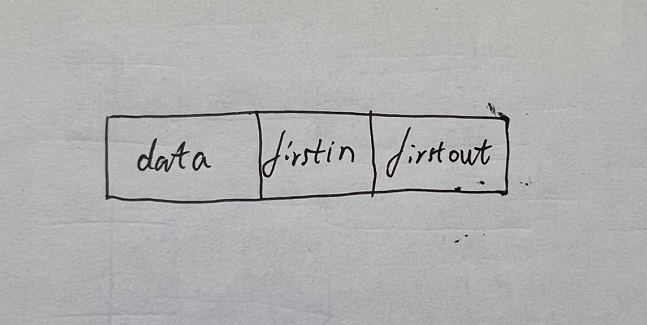
- 顶点表结点:
- firstin表示入边表头指针,指向该顶点的入边表中第一个结点
- firstout表示出边表头指针,指向该顶点的出边表中的第一个结点
- 边表结点:
- tailvex是指弧起点在顶点表的下标
- headvex是指弧终点在顶点表中的下标
- headlink是指入边表指针域,指向终点相同的下一条边
- taillink是指边表指针域,指向起点相同的下一条边
- 如果是网,还可以增加一个weight域来表示权值
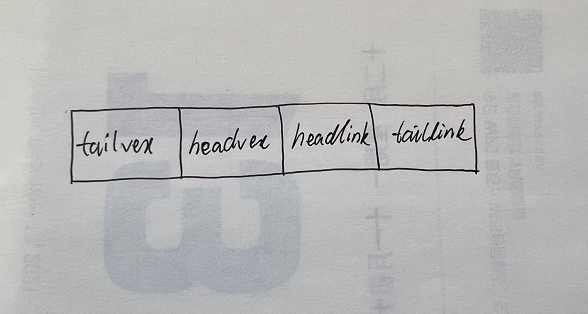
- 十字链表的好处就是把邻接表和逆邻接表整合到一起,这样既容易找到以$v_i$为尾的弧,也容易找到以$v_i$为头的弧,因而容易求得顶点的出度和入度。
- 除了结构复杂一点,创建图算法的时间复杂度和邻接表是相同的。
- 在有向图的应用中,十字链表是非常好的数据结构模型。
4-邻接多重表
5-边集数组
- 边集数组是由两个一维数组构成
- 一个存储顶点的信息
- 一个存储边的信息,这个边数组每个元素由一条边的起点下标、终点下标和权组成
本文为原创文章,版权归Aet所有,欢迎分享本文,转载请保留出处!

你可能也喜欢
- ♥ 大话数据结构_树森林二叉树转换与遍历01/10
- ♥ 栈队列相关09/18
- ♥ 大话数据结构_算法相关&&AVL&&B树相关02/20
- ♥ 狄克斯特拉算法06/29
- ♥ 大话数据结构_图遍历01/27
- ♥ 大话数据结构_二叉树_结构&&遍历&&推导11/03