
基本语法
普通字符
- 字母、数字、汉字、下划线,以及没有被定义特殊意义的标点符号,都是 "普通字符"。
简单转义字符
-
一些不便书写的字符,比如换行符,制表符等,使用 \n,\t 来表示。另外有一些标点符号在正则表达式中,被定义了特殊的意义,因此需要在前面加 "\" 进行转义后,匹配该字符本身。
-
deelx转义字符
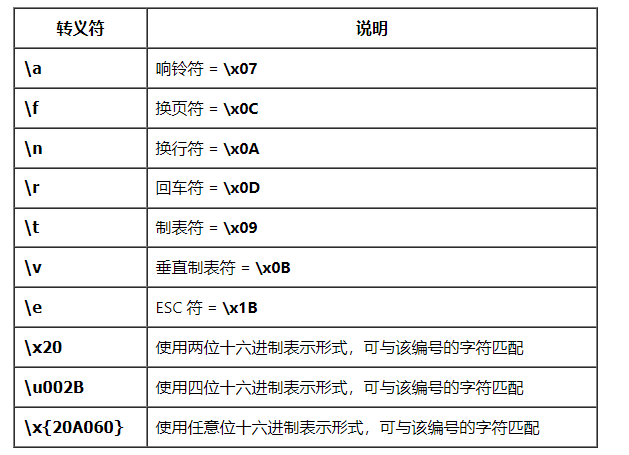
- deelx特殊意义

转义字符
- 使用 \Q 开始,\E 结束,可使中间的标点符号失去特殊意义,将中间的字符作为普通字符。
- 使用 \U 开始,\E 结束,除了具有 \Q...\E 相同的功能外,还将中间的小写字母转换成大写。在大小写敏感模式下,只能与大写文本匹配。
- 使用 \L 开始,\E 结束,除了具有 \Q...\E 相同的功能外,还将中间的大写字母转换成小写。在大小写敏感模式下,只能与小写文本匹配。

字符集合
- 可以匹配 "多个字符" 其中任意一个字符的正则表达式。虽然是 "多个字符",但每次只能匹配其中一个。
- DEELX 正则表达式中标准的字符集合有:
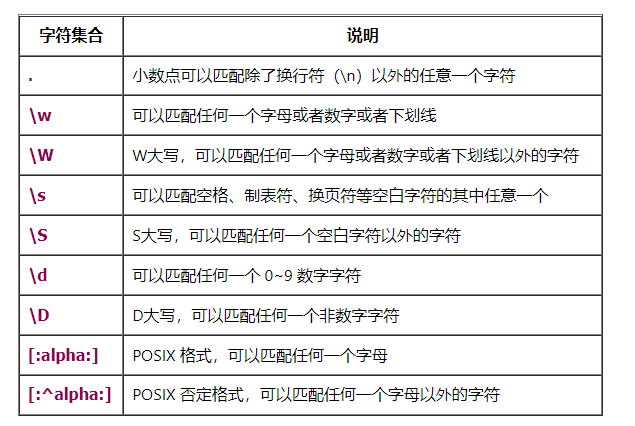
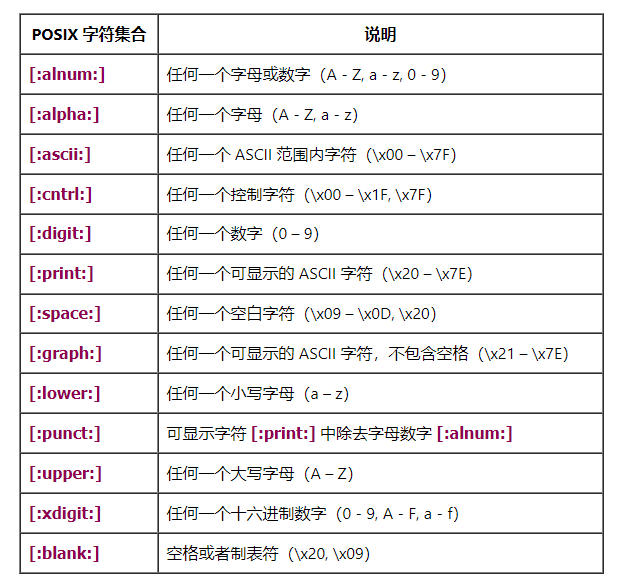
- DEELX 支持的 POSIX 字符集合定义有:
自定义字符合集
- 用中括号 [ ] 包含多个字符,可以匹配所包含的字符中的任意一个。同样,每次只能匹配其中一个。
- 用中括号 [\^ ] 包含多个字符,构成否定格式,可以匹配所包含的字符之外的任意一个字符。
匹配次数限定
-
使被修饰的表达式可多次重复匹配的修饰符。
-
贪婪模式:
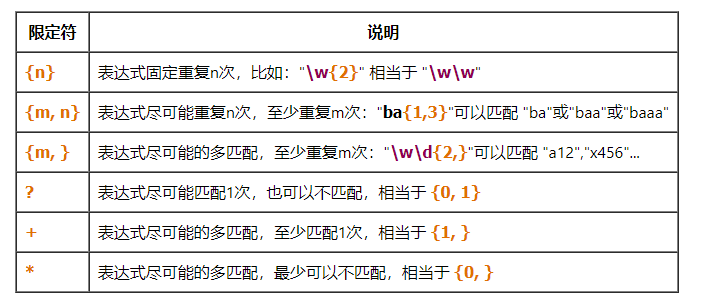
- 勉强模式:
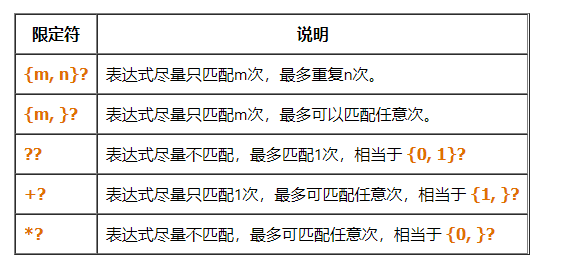
- 占有模式:

字符边界
- 本身不匹配任何字符,只对字符边界和字符间缝隙附加条件的表达式。

选择表达式
- 使用竖线 "|" 分隔多段表达式,整个表达式可匹配其中任意一段。
分组
- 用括号 ( ) 将其他表达式包含,可以使被包含的表达式组成一个整体,在被修饰匹配次数时,可作为整体被修饰。
- 另外,用括号包含的表达式,所匹配到的内容将单独作记录,匹配过程中或结束后可以被获取。
命名分组
- 与普通分组一样的功能,并且将匹配的子字符串捕获到一个组名称或编号名称中。
- 在获得匹配结果时,可通过分组名进行获取。
|
1 |
(?<name> xxx) |
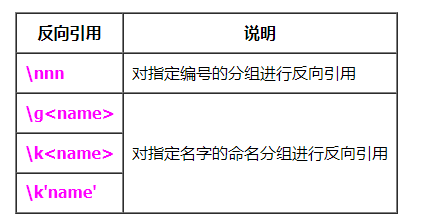
反向引用
- 对指定分组已捕获的字符串进行引用,要求文本中当前位置开始的字符串,必须和指定分组捕获到的字符串一致。
扩展语法
注释
- 格式 (?# xxx ) 可用来表示一段注释。
模式修改符
- 在正则表达式中间,对匹配模式进行修改。
- DEELX 支持对 IGNORECASE, SINGLELINE, MULITLINE, GLOBAL 进行修改。
|
1 |
(?ismg-ismg) |

非捕获组
- 使用 (?: ) 包含其他表达式,可使被包含的表达式组成一个整体,在被修饰匹配次数时,可作为整体被修饰。
- 与普通分组不同的是,非捕获组不记录所匹配的内容,比普通分组更节约内存资源。
|
1 |
(?:xxx) |
预搜索
- 判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符。

独立表达式
- 独立表达式所匹配的内容,与将它单独匹配时匹配的内容一致。不管之后的表达式是否匹配成功,独立表达式内部都不进行回退,都不会再次尝试匹配。
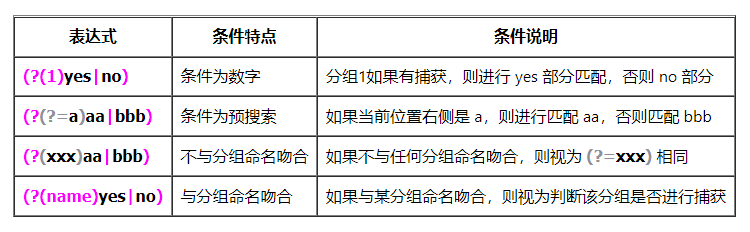
条件表达式
- 根据某个条件是否成立,来选择匹配 2 个可选表达式中的其中一个。
- 可以用于条件表达式的条件有两种类型:
- 指定分组(group)是否进行了捕获。
- 文本中当前位置是否可以与指定表达式匹配。
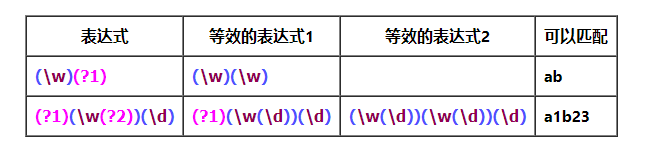
递归表达式
-
对另一部分子表达式的引用,而不是对其匹配结果的引用。当被引用的表达式包含自身,则形成递归引用。
-
相对于 "反向引用" 来说,反向引用是在匹配过程中,对匹配到的字符串内容进行引用,而 "递归匹配" 是对表达式进行引用。示例如下:

- DEELX 支持的递归表达式格式有:
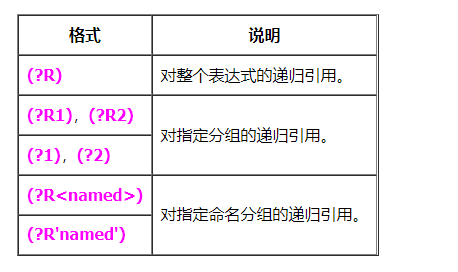
匹配模式
忽略大小写
- IGNORECASE
- 匹配时忽略大小写。默认情况下,正则表达式是要区分大小写的。不管是否指定忽略大小写模式,字符类,比如 [A-Z] 是要区分大小写的。
单行模式
- SINGLELINE
- 使小数点 "." 可以匹配包含换行符(\n)在内的任意字符。默认情况下,小数点只匹配换行符以外的任意字符,不匹配换行符。
多行模式
- 使 ^ 符号除了能够匹配字符串开始位置外,还能匹配换行符(\n)之后的位置;使 \$ 符号除了能够匹配字符串结束位置外,还能匹配换行符之前的位置。默认情况下, ^ 符号只能匹配字符串开始位置, $ 符号只能匹配字符串结束位置。
- SINGLELINE 和 MULTILINE 虽然听起来相互矛盾,但却是作用在不同的地方。因此它们是可以组合使用的。
- 在指定了 MULTILINE 之后,如果需要仅匹配字符串开始和结束位置,可以使用 \A 和 \Z。
全局模式
- 使 \G 可以用来匹配本次查找匹配的开始位置,对于连续的匹配来说,也就是上次匹配的结束位置。默认情况下, \G 没有作用。
- DEELX 在进行替换操作(Replace)时,不管是否指定 GLOBAL 模式,DEELX 都可以进行所有的替换。是否指定 GLOBAL 模式只是对 \G 起作用。如果希望进行有限次数的替换,可在替换操作时指定替换次数。
从左向右模式
- RIGHTTOLEFT
- 从右向左的进行匹配。从被匹配字符串的结束位置向前进行查找匹配,同时,在表达式中也是右侧的表达式先进行匹配。
- 表达式的写法仍然按原来的习惯:匹配次数修饰符(*, +, {n}, ……)仍然位于被修饰部分的右侧而不是左侧;^ 仍然匹配文本开始而不是文本结束;(?=xxx) 仍然是正向与搜索(向右预搜索),而不是向左;分组(group)编号仍然是从左向右进行编号;等等
- 不管整个表达式是否指定了 RightToLeft 模式,"反向预搜索(反向零宽度断言)" 内的表达式始终采用 RightToLeft 模式。
扩展模式
- 使 DEELX 忽略表达式中的空白字符,并且把从 # 开始到该行行末的内容视为注释。
- 默认情况下,正则表达式中的空格,换行等字符将可以匹配相应的字符。指定了 EXTENDED 模式后,如果要在正则表达式中表示空白字符比如空格符号(space)时,应该用 \x20 表示,如果要在表达式中表示 # 符号,应该用 # 表示。
- 不管是否指定了 EXTENDED 模式,括号内以 ?# 号开始时,比如(?# xxx ),那么这一对括号以及包含的内容都始终作为注释而被忽略。
替换
$1-$999
- 代表某个捕获组捕获到的内容
- 如果捕获组编号大于表达式中的最大捕获组编号,那么 DEELX 会减少数字个数,以使捕获组编号小于或等于最大编号;而把剩余的数字看作字符串常量。
- 当前最大捕获组编号为 20,那么,指定替换为 "\$999" 将被看作 "\$9" + "99";指定替换为 "\$15" 将代表第 15 个捕获组。如果本来就是想把 "5" 当成字符串常量时("\$1" + "5"),可以使用 \$0015 表示,DEELX 最多识别 3 位 10 进制数字。
${name}
- 代表指定命名分组捕获到的内容
$$
- 表示一个 \$ 符号
$&
- 代表每次匹配到内容
$`
- 代表原字符串中,匹配到的内容之前的字符串
$'
- 代表原字符串中,匹配到的内容之后的字符串
$+
- 代表所有“有捕获”的分组中,编号最大的那个分组
- 举例:"aaa(b+)|ccc(b+)" 在匹配 "aaabbb" 时,虽然最大分组是第2个分组,但最大“有捕获”的是第1个分组,此时的 \$+ 代表 \$1 。
$_
- 代表被替换的整个字符串。"_" 是下划线。
本文为原创文章,版权归Aet所有,欢迎分享本文,转载请保留出处!

你可能也喜欢
- ♥ 正则表达式 _ 断言01/17
- ♥ 正则表达式_匹配模式02/24
- ♥ 正则表达式_常用表达式02/24
- ♥ 匹配_KMP模式匹配算法:一11/02
- ♥ 【Javascript】对象引用复制05/18
- ♥ cef:任务、IPC、网络相关04/30
热评文章
- 正则表达式 _ 量词 0
- 正则表达式_字符组 0
- Deelx正则引擎使用 0
- 正则表达式_常用表达式 0
- 正则表达式_匹配模式 0
- 正则表达式 _ 断言 0